
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Learn more about how the Verida Confidential Compute API's ensure maximum data privacy and how that impacts API performance.
When an AI request is made to access user data, the data is queried within the Verida confidential compute environment (see Privacy & Security).
This environment operates entirely in memory for maximum security. As a result encrypted user data must be downloaded from the Verida network, decrypted in-memory, and then processed. Depending on the type and volume of data being requested, this can take seconds through to many minutes.
A simple query such as "how many emails have I sent" requires the following steps:
Authenticate the provided API token [milliseconds]
Connect to the Verida network [seconds]
Download the user's data from the email database [seconds - minutes depending on data volume]
Decrypt the user data [seconds - minutes depending on data volume]
Query all the user data with a filter to only find emails I have sent [seconds]
Return the result [milliseconds]
The confidential compute environment implements caching (see below), so the above steps 2-4 are only required on the first request.
In order to increase performance, the confidential compute environment caches (in encrypted memory) the user's Verida network connection and any downloaded user data.
This cache currently expires after 30 minutes of inactivity, so if there is a delay of 30 minutes between requests, the caching has no impact.
Storing data in memory is expensive, so there is a cost / benefit consideration to how long data should be kept in memory.
Have a dynamic caching model that learns user's usage patterns and customizes cache duration and timing.
Enabling users to configure their caching model and directly relate to the cost of accessing the service (ie: Pay a little extra to always have user data available between 7am - 10am).
Enable on-disk encryption of cached data to avoid it being downloaded over and over again; there are important privacy / security implications and decentralized architecture considerations that require careful thought with this model.
Coming soon.
What tutorials would you like to see?
Learn about the LangGraph / LangChain tools for accessing private user data
Our first release supports typescript LangGraph tools to easily integrate with any LangChain / LangGraph application.
You can locally run the to access your data stored in your to experiment and learn what is possible.
You can integrate these tools into your existing LangGraph / LangChain project, see the for example code snippets and instructions.
Coming soon
auth_token securely. Unauthorized access to this token could compromise your application and user data.const API_ENDPOINT = "https://api.verida.ai/api/rest/v1/auth";
// Obtain token from localstorage (or your own database)
const authToken = localStorage.getItem("veridaAuthToken") || "";
// Example: search/universal endpoint
$.get({
url: `${API_ENDPOINT}/search/universal?keywords=meeting+agenda`,
headers: {
"Authorization": `Bearer ${authToken}`,
"Content-Type": "application/json"
},
success: (response) => {
console.log(response);
// Handle the response data
}
});You can access the full API reference here:
Coming soon
Overview of how Verida AI works
Verida AI allows users to easily and quickly connect their private data from other applications into your application or AI product. Once integrated, your AI application can access a user's Gmail, Calendar, Drive, Telegram and much more.
Your user creates an account in the Verida Vault (https://app.verida.ai/) that manages all their private data and application connections.
If a user doesn't have an account, they will be prompted to create one when they connect to your application.
Once a user has a Verida Vault account, they can connect to existing third party platforms they use (ie: Google, Telegram, Discord etc.). The Verida Vault will then start syncronizing the user's data in the background. This data is encrypted with private keys owned by the user and stored on the Verida Network.
This works very similar to "Connect Google" or "Connect Facebook" buttons, enabling a user to authorize your application to access their data.
A user clicks a "Connect Verida" button in your application (see and ) and is redirected to the Verida Vault and is presented with a screen allowing them to allow your application to access their data.
Once the user has allowed access, they will be redirected to your application and an API auth token will be included in the URL query parameters.
This API auth token can then be used:
For a integration such as .
To make direct API requests using the .
Test this complete flow using the
Get started with the Verida AI API's and LLM tools
Welcome to the Verida AI developer documentation!
Here, you’ll find everything you need to integrate Verida’s AI developer tools into your application.
Verida AI allows users to easily and quickly connect their private data from other applications into your application or AI product. Once integrated, your AI application can access a user's Gmail, Calendar, Drive, Telegram and much more.
See How it worksto learn how your application can easily access user's data.
Easy Data Access: With a single integration gain access to user data across many different platforms and data sources.
Flexible Integration: Use our integrations (such as ) or use our REST APIs directly for server or client-side applications.
User-Owned Data: Allow your application to access user data, while keeping users in control of their data, enhancing privacy and trust.
: Learn the flow of how your application can gain access to data directly from users
: Open the developer console, an easy to use interface to generate authorization requests and use APIs.
: Decide which data or APIs your application needs access to, and request only the necessary scopes.
Implement Authentication: Set up a "Connect Verida" button in your application so users can grant you the required permissions.
API Reference:
GitHub Repos & Examples:
Community & Support: for direct feedback and support.
We’re excited to see what you build with Verida. Let’s get started!
Learn where to get developer help when building with Verida AI
Join the #verida-ai channel on Discord
Discourse forum (coming soon)
Reach out to if you want to contact the team.
We will soon be offering office hours for developers to get direct support from the Verida core engineering team.
Learn how to obtain a Verida API key to access user data
There are currently three ways to obtain an API key to use the Verida APIs:
Generate your own key with the Verida Vault
Generate your own key with the Developer console
Request a key from a user of your application
Learn about the available API endpoints
— Access data of a particular type (ie: emails) and apply filters, sorting and response limits.
— Perform keyword searches over particular data types or all data.
— Perform LLM requests using a model with a RAG pipeline that can access user data.
Learn how to get started with the Verida AI developer console
The Verida AI is the central hub for managing your Verida developer account, monitoring your application usage, and interacting with our API ecosystem. This guide will walk you through the key capabilities and features of the console, empowering you to build, test, and deploy applications using the Verida platform.
Before diving into development, you must create a Verida account to manage your developer account. This account will serve as your identity within the Verida ecosystem and unlock access to various features of the developer console.
Steps to Create Your Account:
Coming soon, the ability to perform actions on behalf of a user, via standardized API's.
Send Email
Send Telegram message
Post Youtube video / comment
Learn about the Verida Vault for managing user data and application connections
The provides an easy web interface for users to manage their personal data, connect to third party applications, and pull their data from centralized platforms.
Users can pull their personal data from platforms such as Meta, Google, X, Email, LinkedIn, Strava, and much more. This data is encrypted and stored in a user-controlled personal data Vault on the Verida network.
The Vault provides also provide a universal search connected to the user's data; enabling easy search across emails, message history, documents and more.
Users can accept data access requests from third party applications, allowing them to connect their personal data with emerging personal AI applications.
Order Uber
Granular Permissions: Precisely control access with scopes, ensuring minimal data exposure.
Decentralized Identity: Seamlessly manage decentralized identities across applications.
Open Source: Work with open-source, community driven software.
Integrate with your application:
Use LangGraph tools: Quickly expand the capabilities of your LLM with our pre-built LangGraph tools that can access all available user data.
Use the APIs: Make calls to the Verida User APIs with a valud user auth_token .
Explore Examples: Head to our code samples and tutorials to see best practices in action.
Actions— Perform actions on behalf of a user with their connected services (ie: Send a Telegram message)
Other Endpoints— Miscellaneous endpoints (ie: Information about connected accounts).
A simple command line chat bot that uses the PersonalAgentKit langchain tools.
Source code: https://github.com/verida/personal-agent-kit/blob/main/typescript/examples/chatbot/README.md
A simple demo of a Telegram dashboard using the Verida API's.
Credit: Rishi Rawat from Cluster Protocol.



Note: To generate your own key, you will need to first create a self-custody Verida Account.
You can generate your own private API key from the Verida Vault (https://app.verida.ai/), in the Authorized Apps menu item.
You can generate your own private API key from the Developer Console (https://admin.verida.ai/), in the Generate Token menu item.
If you are building an application, you can request a key directly from the user by embedding a Connect Verida button into your application with pre-configured scopes to request from a user.
See the Developer Console and Authentication sections of the documentation to learn more.
Install Verida Wallet: Visit the Verida Wallet page to download the Verida Wallet.
Create Verida Account: Within the wallet, create your decentralized Verida account and backup your seed phrase.
Log In: Once setup, scan the QR code in the Developer Console to get started.
After setting up your Verida account, take the next step by registering as a developer. This process provides you with free credits to experiment with and develop your applications.
How to Register as a Developer:
Login: Login to the Developer Console and navigate to the Dashboard.
Register Developer Account: Click on the "Register as a Developer" button.
Receive Free Credits: Once verified, your account will be credited with free API credits, enabling you to start building and testing your applications immediately.
The dashboard is your control center within the Verida AI Developer Console. It offers real-time insights and detailed metrics about your application's performance and usage.
Key Metrics Displayed:
Credit Balance: Monitor the number of free credits available for API requests.
API Requests: Track the number of API calls made by your application.
User Connections: See how many users have connected to your application, giving you a snapshot of your app’s engagement and reach.
This overview helps you manage resources effectively and plan for scaling your applications as usage grows.
The Developer Sandbox is a powerful feature designed to facilitate experimentation and streamline your development process. It provides a secure, controlled environment where you can perform a variety of tasks.
Build Auth Requests:
Create authentication requests to obtain auth tokens for accessing user data.
Customize request parameters and scopes to fit your application’s needs.
Manage API Scopes:
List all available API scopes.
Add, modify, or remove scopes as required.
Understand the permissions each scope provides for granular access control.
Make API Requests:
Test your API endpoints directly from the sandbox.
Validate responses and debug issues in real time.
Ensure your requests are correctly formatted and authenticated.
Browse Data with an Auth Token:
Use your obtained auth tokens to query and browse data.
Visualize and inspect data returned from your API calls.
Confirm data integrity and response structures before deploying to production.
The sandbox is an essential tool that enables you to build, test, and refine your application logic without affecting your live environment.
Dive deeper into the technology, architecture and design decisions that power Verida AI
Artificial Intelligence (AI) is rapidly evolving beyond simple prompts and chat interactions. While tools like ChatGPT and Meta AI have made conversations with large language models (LLMs) commonplace, the future of AI lies in agents—sophisticated digital entities capable of knowing everything about us and acting on our behalf. Let’s dive into what makes up an AI agent and why privacy is a crucial component in their development.
How fast can data, stored in a decentralized database storage network like Verida, be made available to a personal AI agent? This is a critical question as huge time lags will create a poor user experience, making any personal AI products unviable.
The Verida Network provides storage infrastructure perfect for AI solutions and the upcoming data connector framework will create a new data economy that benefits end users.
, ,
This Technical Litepaper presents a high-level outline of how the Verida Network is growing beyond decentralized, privacy preserving databases, to support decentralized, privacy-preserving compute optimized for handling private data.
Verida’s Search APIs let you perform powerful keyword-based searches across multiple data sources. Each search endpoint uses the specified credit amount per call.
HTTP Method & Endpoint: GET /search/chat-threads
Summary: Search through all chat threads for matching keywords.
Credit Usage: 2 credits
Scope: api:search-chat-threads
Example:
Full Documentation: Search: Chat Threads
HTTP Method & Endpoint: GET /search/ds or POST /search/ds
Summary: Perform a keyword search across a specific datastore.
Credit Usage: 1 credit
HTTP Method & Endpoint: GET /search/universal
Summary: Perform a keyword search across all user data (datastores, databases, etc.) the user has granted access to.
Credit Usage: 2 credits
As an AI developer you may be asking, does Verida offer a Vector Database over user data?
We currently don't, because from our testing Vector Databases require more resources to create than a traditional high performance keyword index and produces sub-par results when working with user data.
We are happy to re-assess this if there's a use case that specifically requires a Vector Database.
Read more about the recently announced AI grants program:
There are three types of key grants:
Connector Grants: Build new connectors for extracting data from web2 into a user's Verida Vault. Apply here.
Developer Credits: Apply for VDA credits to power your Verida AI application. .
Builder Grants: Access grants for building AI applications using the Verida AI technology stack
Verida AI offers a flexible pricing model that allows you to manage API costs effectively while scaling your application. Below is an overview of how pricing works on our platform.
Credit Value: Each credit is valued at 0.01 USD.
API Request Consumption:
Standard API Requests: Most API requests consume 1 credit per call.
Intensive API Requests: More resource-intensive operations (e.g., LLM processing or heavy searches) may consume multiple credits.
When your application requests access to user data, you have two payment options for covering API request costs:
User-Paid Requests:
The user authorizes and pays for the API requests initiated by your application.
Developer-Paid Requests:
Your application bears the cost for the API requests.
This flexibility ensures that you can choose the model that best suits your application's business logic and user experience.
If you need to increase your credit balance, you can purchase additional credits by acquiring Verida tokens (VDA) and converting them into credits directly through the .
Conversion Process:
Purchase VDA: Acquire Verida tokens from .
Convert VDA to Credits: Use the Developer Console to convert your VDA into credits.
Dynamic Pricing with VDA: The conversion rate between VDA and credits is calculated dynamically at the time of each API request. This means that the amount of VDA deducted per API call reflects the current VDA price.
This dynamic pricing model ensures that the cost of API usage remains transparent and reflective of current market conditions.
Overview of current Artificial Intelligence use cases built on the Verida Network
The Verida infrastructure enables application developers to build AI products and services using private user data.
Big tech own us all. They own our data and they monetize our data without any of that value being returned to us. With Verida, we enable users to take custody of their data and use it at their leisure thanks to selective disclosure and permissioned access. Users have full control and choice.
Verida enables developers to build hyper-personalized AI agents based on your data or aggregated user data, without compromising individual information. The problem with big tech data usage is that individual data packets can be traced back to you as a user. But this is no longer necessary. Verida's confidential infrastructure enables user data to be pooled so the underlying information is available for LLM's to learn and benefit, without this data being tied to you as an individual, in turn delivering a more equitable result for both user and application.


A breakdown of the key components that will make up our future AI Agents
Artificial Intelligence (AI) is rapidly evolving beyond simple prompts and chat interactions. While tools like ChatGPT and Meta AI have made conversations with large language models (LLMs) commonplace, the future of AI lies in agents—sophisticated digital entities capable of knowing everything about us and acting on our behalf. Let’s dive into what makes up an AI agent and why privacy is a crucial component in their development.
1. The Brain: The Core of AI Computation
Every AI agent needs a "brain"—a system that processes and performs tasks for us. This brain is an amalgamation of various technologies:
Large Language Models (LLMs): The foundation of most AI agents, these models are trained to understand and generate human-like responses.
Fine-Tuning: A step further, where LLMs are tailored using personal data to offer more personalized and accurate outputs.
Retrieval-Augmented Generation (RAG): A method that smartly incorporates user data into the context window, helping the LLM access relevant personal information and provide more meaningful interactions.
Databases: Both vector and traditional databases come into play, enabling the AI agent to store and retrieve vast amounts of information efficiently.
The synergy of these technologies forms an AI's cognitive abilities, allowing it to generate intelligent and context-aware responses.
2. The Heart: Data Integration and Personalization
An AI agent's brain is only as good as the data it has access to. The "heart" of the AI agent is its data engine, which powers personalization. This engine requires access to various types of user data, such as:
Emails and Private Messages: Insights into communication preferences.
Health Records and Activity Data: Information from fitness trackers or health apps like Apple Watch.
Financial Records: Transaction histories and financial trends.
Shopping and Transaction History: Preferences and past purchases for tailored shopping experiences.
The more data an AI agent has, the better it can serve as a "digital twin," representing and anticipating user needs.
3. The Limbs: Acting on Your Behalf
For an AI agent to be genuinely useful, it must do more than just think and understand—it needs the capability to act. This means connecting to various services and APIs to:
Book Flights or Holidays: Manage travel arrangements autonomously.
Order Services: Call for a ride, order groceries, or make appointments.
Send Communications: Draft and send emails or messages on your behalf.
To enable these capabilities, the agent must be seamlessly integrated with a wide array of digital services and platforms, with user consent being a critical aspect.
4. Privacy and Security: The Final Piece
As these agents become more capable and integrate deeply into our lives, ensuring privacy and security is paramount. The more data an agent holds, the more vulnerable it becomes to potential misuse. Here's why this matters:
Self-Sovereign Technologies: The ideal future of AI agent technology is built on decentralized and self-sovereign systems. These systems empower users as the sole owners of their data and AI computation.
Guarding Against Big Tech Control: Companies like Google, Apple, and Microsoft already possess vast amounts of user data. Concentrating even more data into their control can lead to potential exploitation. A decentralized model prevents these corporations from having unrestricted access to personal AI agents, ensuring that only the user can access their private information.
Final Thoughts
For AI agents to flourish and be trusted, they must be built on a foundation that respects user privacy and autonomy. In essence, a robust AI agent will consist of:
A Brain: Advanced AI computation.
A Heart: A rich data engine powered by user data.
Limbs: The ability to take action on behalf of the user.
However, without strong privacy and security measures, these agents could pose significant risks. The future of AI agents hinges on creating a technology layer that preserves individual ownership, enforces privacy, and limits the control of major tech companies. By ensuring that only the agent’s owner can access its data, we set the stage for a safer, more empowering digital future.
Examples:
If VDA is 0.01 USD and your API call consumes 1 credit, you will use 1 VDA.
If VDA is 0.10 USD and your API call consumes 1 credit, you will use 0.1 VDA.
Scope: api:search-ds
Example:
Full Documentation: Search: Datastore
api:search-universalExample:
Full Documentation: Search: Universal
# Using GET
curl -X GET "https://api.verida.ai/api/rest/v1/search/ds?keywords=invoice&datastore=social-email" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN"curl -X GET "https://api.verida.ai/api/rest/v1/search/universal?keywords=meeting+agenda" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN"curl -X GET "https://api.verida.ai/api/rest/v1/search/chat-threads?keywords=urgent" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN"High quality data is necessary to train AI models. Verida provides infrastructure allowing individuals to extra their data from existing platforms (ie: social, health, finance, messaging) and consensually share that data with AI data marketplaces.
Data marketplaces can be built to request data from end users via , verify the authenticity of data via the Verida Network and even reward end users with crypto.
Data pools can be created, and then connected to AI models, to provide expert knowledge bases built on private user data, without exposing the actual user data.
Verida enables private user data to be connected to Large Language Models (LLM) via RAG to create powerful, personalized AI products and services.
For example:
Query a user's private AI prompt to provide personalized services (ie: Where have I travelled in the last 5 years? to then provide recommendations on a holiday for next year)
Query a user's private data to feed into a custom RAG pipeline to personalize an existing product or service
The Verida Data Bridge infrastructure enables users to connect to third party APIs and extract their data. This user data can then be used by AI agents to know everything about a user.
Verida is building out self-sovereign infrastructure (leveraging Trusted Execution Environments) that operates in secure enclaves to enforce privacy and security of user data and any computation that occurs. This differs from current cloud AI (OpenAI, Groq, etc.) which run on non-privacy preserving, generic compute.
This is ideally suited for confidential AI:
Training of new models
Inference for AI prompts
Agents acting on behalf of users
These compute resources have direct, fast, access to user data via .
This tutorial will walk through how to use Verida API's to access user data, with a focus on accessing Telegram data.
If you haven't already, register a Verida Account, sign into the Developer Console and obtain an Auth token so you can make API requests.
Once you have an auth token, you must include it in your API requests.
Here are some examples of API requests to the AI agent endpoint.
Command line (via curl):
Node.js:
When a user connects their Telegram account, their groups and messages are syncronized and the data is normalized into common data types. See to learn more.
Telegram populates two data schemas:
Social Chat Group ()
Social Chat Message ()
We need to query these schemas using the API endpoint.
Let's start with an example to fetch all the Telegram chat groups a user is in. We need to make an API request to the /ds/queryendpoint (https://api.verida.ai/api/rest/v1/ds/query/).
This endpoint takes a schema, in our case we want the social chat group schema (), however we don't send the actual schema URL, we base64 encoded it.
Node.js example:
.
Let's now fetch all of a user's Telegram messages. Instead of querying the Chat Group datastore, we need to query the Chat Message datastore.
We also want to fetch only telegram messages, so apply a filter:
.
We can update the queryto restrict to only include results from:
A particular group
Messages sent by me
Messages sent after Jan 1st 2025
You may want to make requests such as:
How many messages sent by a user?
How many groups is a user part of?
It is possible to use the /query API endpoint and loop through all the pages of data to count, but that is highly inefficient.
This functionality will be coming very shortly with a new /count endpoint.
You may want to learn more about a user's profile on Telegram, for example:
Is the account verified?
Phone number
Username
Profile pic
This data is currently syncronized, but not available via the API.
This functionality will be coming very shortly with a new /profile endpoint
Learn how Verida APIs enforce privacy and security of user data within a decentralized environment
Verida APIs are built on a first iteration of the Verida Confidential Compute infrastructure. They are designed to find the optimum balance between decentralization, security, privacy and performance.
Verida APIs are running within a confidential computation environment. This means that no-one, not even the underlying infrastructure provider running the API server can access any user data or view the computation occurring on the node.
The first iteration of Verida's Confidential Compute nodes are running inside Marlin Oyster Trusted Execution Environments (TEE). These nodes provide numerous security guarantees and capabilities:
Computation occurs within a secure enclave where the node operator has zero visibility
SSL terminates within the secure enclave, eliminating man-in-the-middle attacks
Server code is verified to be the expected code
No data is stored to external disks. All data is secured in memory.
The Verida Foundation is operating the first cohort of Confidential Compute nodes and will open up to node operators in the future.
Verida APIs integrate the within the secure enclave on each confidential compute node. User data is syncronized from the Verida network, decrypted and then loaded into memory for rapid access via API endpoints.
As such, user data retains all the security and privacy benefits of the Verida Network and user data never leaves the secure enclave, accept via user authorized API requests.
Important privacy notice for the beta release
The large language models (LLM) currently used in the Verida APIs are not currently running in a Verida Confidential Compute secure enclave. Secure enclaves do not currently support GPU access which is necessary for performant LLM operations.
The beta release provides the option of using or your own LLM.
This is a temporary solution as we are collaborating with partners to enable LLM's to run efficiently and cost effectively within secure enclaves. While this is not perfect, we believe the provides adequate protections for this alpha release, while those with highly sensitive requirements can still provide their own custom LLM.
From the AWS documentation:
Amazon Bedrock doesn't store or log your prompts and completions. Amazon Bedrock doesn't use your prompts and completions to train any AWS models and doesn't distribute them to third parties.
AWS complies with ISO 27018, a code of practice that focuses on protection of personal data in the cloud. It extends ISO information security standard 27001 to cover the regulatory requirements for the protection of personally identifiable information (PII) or personal data for the public cloud computing environment and specifies implementation guidance based on ISO 27002 controls that is applicable to PII processed by public cloud service providers. For more information, or to view the AWS ISO 27018 Certification, see the webpage
You can provide your own OpenAI compatible LLM endpoint and API key through the LLM API's, except the Agent endpoint as it requires a proprietary LLM to perform at it's best.
The source code for the APIs are open source and are contained within the .
HTTP Method & Endpoint: GET /connections/profiles
Summary: Fetch the profile of a connection (ie: "google" or "telegram").
Credit Usage: 0 credits
Scope: api:connections-profiles
Example:
Full Documentation:
HTTP Method & Endpoint: GET /connections/status
Summary: Access status information on connected third party accounts (ie: Google, Telegram).
Credit Usage: 0 credits
Top Three Data Privacy Issues Facing AI Today. AI has taken the world by storm, but there are some critical privacy issues that need to be considered.
AI (artificial intelligence) has caused frenzied excitement among consumers and businesses alike – driven by a passionate belief that LLMs (large language models) and tools like ChatGPT will transform the way we study, work and live.
But just like in the internet’s early days, users are jumping in without considering how their personal data is used – and the impact this could have on their privacy.
There have already been countless examples of data breaches within the AI space. In March 2023, OpenAI temporarily took ChatGPT after a ‘significant’ error meant users were able to see the conversation histories of strangers.
That same bug meant the payment information of subscribers – including names, email addresses and partial credit card numbers – were also in the public domain.
Learn how to generate an authentication token to access user data
This guide explains how to authenticate users in your application to obtain an auth_token, and make API requests to Verida’s services.
To access user data via Verida APIs, you must include a valid auth_token in every request. This token can be generated using Verida's authorization endpoints and stored securely by your application for future requests.
Learn about the Verida PersonalAgentKit
The Verida provides integrations with AI frameworks for simple integration into your applications.
For the first release, we support tools to easily integrate with any LangChain / LangGraph application.
Verida PersonalAgentKit supported the following tools:
Profiles — Allow the LLM to know about your external profiles (ie: Google or Telegram accounts)
Query — Allow the LLM to query your data (ie: Query your emails, message history, Youtube favourites etc.)
Overview of Data APIs with links to full documentation
Verida supports a network of decentralized, confidential APIs to simplify access to data stored within decentralized accounts on the Verida Network.
Verida’s LLM APIs enable your application to run Large Language Model prompts. Depending on the scope granted, these prompts can range from basic text generation to context-enriched prompts powered by user data. Below is an overview of the available LLM endpoints, the required scopes, and their respective credit costs.
The emergence of Decentralized Physical Infrastructure Networks (DePIN) are a linchpin for providing privacy preserving decentralized infrastructure to power the next generation of large language mode
Artificial intelligence (AI) has become an undeniable force in shaping our world. From personalized recommendations to medical diagnosis, AI's impact is undeniable. However, alongside its potential lies a looming concern: data privacy. Traditional AI models typically rely on centralized data storage and centralized computation, raising concerns about ownership, control, and potential misuse.
See part 1 of this series, “”, for a breakdown of key privacy issues which we will explain how web3 can help alleviate these problems.
The emergence of Decentralized Physical Infrastructure Networks (DePIN) are a linchpin for providing privacy preserving decentralized infrastructure to power the next generation of large language models (LLMs).
In September 2023, a staggering 38 terabytes of Microsoft data was inadvertently leaked by an employee, with cybersecurity experts warning this could have allowed attackers to infiltrate AI models with malicious code.
Researchers have also been able to manipulate AI systems into disclosing confidential records.
In just a few hours, a group called Robust Intelligence was able to solicit personally identifiable information from Nvidia software and bypass safeguards designed to prevent the system from discussing certain topics.
Lessons were learned in all of these scenarios, but each breach powerfully illustrates the challenges that need to be overcome for AI to become a reliable and trusted force in our lives.
Gemini, Google’s chatbot, even admits that all conversations are processed by human reviewers – underlining the lack of transparency in its system.
“Don’t enter anything that you wouldn’t want to be reviewed or used,” says an alert to users warns.
AI is rapidly moving beyond a tool that students use for their homework or tourists rely on for recommendations during a trip to Rome.
It’s increasingly being depended on for sensitive discussions – and fed everything from medical questions to our work schedules.
Because of this, it’s important to take a step back and reflect on the top three data privacy issues facing AI today, and why they matter to all of us.
Tools like ChatGPT memorize past conversations in order to refer back to them later. While this can improve the user experience and help train LLMs, it comes with risk.
If a system is successfully hacked, there’s a real danger of prompts being exposed in a public forum.
Potentially embarrassing details from a user’s history could be leaked, as well as commercially sensitive information when AI is being deployed for work purposes.
As we’ve seen from Google, all submissions can also end up being scrutinized by its development team.
Samsung took action on this in May 2023 when it banned employees from using generative AI tools altogether. That came after an employee uploaded confidential source code to ChatGPT.
The tech giant was concerned that this information would be difficult to retrieve and delete, meaning IP (intellectual property) could end up being distributed to the public at large.
Apple, Verizon and JPMorgan have taken similar action, with reports suggesting Amazon launched a crackdown after responses from ChatGPT bore similarities to its own internal data.
As you can see, the concerns extend beyond what would happen if there’s a data breach but to the prospect that information entered into AI systems could be repurposed and distributed to a wider audience.
Companies like OpenAI are already facing multiple lawsuits amid allegations that their chatbots were trained using copyrighted material.
This brings us neatly to our next point – while individuals and corporations can establish their custom LLM models based on their own data sources, they won’t be fully private if they exist within the confines of a platform like ChatGPT.
There’s ultimately no way of knowing whether inputs are being used to train these massive systems – or whether personal information could end up being used in future models.
Like a jigsaw, data points from multiple sources can be brought together to form a comprehensive and worryingly detailed insight into someone’s identity and background.
Major platforms may also fail to offer detailed explanations of how this data is stored and processed, with an inability to opt out of features that a user is uncomfortable with.
Beyond responding to a user’s prompts, AI systems increasingly have the ability to read between the lines and deduce everything from a person’s location to their personality.
In the event of a data breach, dire consequences are possible. Incredibly sophisticated phishing attacks could be orchestrated – and users targeted with information they had confidentially fed into an AI system.
Other potential scenarios include this data being used to assume someone’s identity, whether that’s through applications to open bank accounts or deepfake videos.
Consumers need to remain vigilant even if they don’t use AI themselves. AI is increasingly being used to power surveillance systems and enhance facial recognition technology in public places.
If such infrastructure isn’t established in a truly private environment, the civil liberties and privacy of countless citizens could be infringed without their knowledge.
There are concerns that major AI systems have gleaned their intelligence by poring over countless web pages.
Estimates suggest 300 billion words were used to train ChatGPT – that’s 570 gigabytes of data – with books and Wikipedia entries among the datasets.
Algorithms have also been known to depend on social media pages and online comments.
With some of these sources, you could argue that the owners of this information would have had a reasonable expectation of privacy.
But here’s the thing – many of the tools and apps we interact with every day are already heavily influenced by AI – and react to our behaviors.
The Face ID on your iPhone uses AI to track subtle changes in your appearance.
TikTok and Facebook’s AI-powered algorithms make content recommendations based on the clips and posts you’ve viewed in the past.
Voice assistants like Alexa and Siri depend heavily on machine learning, too.
A dizzying constellation of AI startups is out there, and each has a specific purpose. However, some are more transparent than others about how user data is gathered, stored and applied.
This is especially important as AI makes an impact in the field of healthcare – from medical imaging and diagnoses to record-keeping and pharmaceuticals.
Lessons need to be learned from the internet businesses caught up in privacy scandals over recent years.
Flo, a women’s health app, was accused by regulators of sharing intimate details about its users to the likes of Facebook and Google in the 2010s.
AI is going to have an indelible impact on all of our lives in the years to come. LLMs are getting better with every passing day, and new use cases continue to emerge.
However, there’s a real risk that regulators will struggle to keep up as the industry moves at breakneck speed.
And that means consumers need to start securing their own data and monitoring how it is used.
Decentralization can play a vital role here and prevent large volumes of data from falling into the hands of major platforms.
DePINs (decentralized physical infrastructure networks) have the potential to ensure everyday users experience the full benefits of AI without their privacy being compromised.
Not only can encrypted prompts deliver far more personalized outcomes, but privacy-preserving LLMs would ensure users have full control of their data at all times – and protection against it being misused.
Get Record — Allow the LLM to fetch a specific record (ie: A specific file or a specific email)
Chat Search — Allow the LLM to perform a keyword search of your message chat threads
Datastore Search — Allow the LLM to perform a keyword search across any of your supported data (ie: Find all emails that mention "utility bills")
Universal Search — Allow the LLM to perform a keyword search across all your data (ie: Find all mentions of "devcon 2025" in all my messages, emails and favourites)
User Information — Allow the LLM to know more about the user account (DID) on the Verida network and what data permissions it can access.
Not all LLM's are created equal. When you use these tools, the LLM must be capable of understanding the tool description and parameters to correctly call the tools in a useful way to respond to a user's prompt.
Here is what we have learned about leading LLM's to date:
Llama 3.3-70B — Recommended. Works well. Open source.
Claude Haiku 3.5 — Recommended. Works very well.
OpenAI (gpt-4o-mini, gpt-4o) — Not recommended. It fails to leverage the selector and sort parameters from the Query tool for no obvious reason.
The following LLM providers support the OpenAI API format, so can be easily used with the OpenAI LangGraph plugin.
Get a RedPill AI key (Highly secure, runs Llama 3.3-70B in a TEE, slow)
Get an Anthropic key (for Claude)
Get a Groq key (Groq is fast)
We recommend using LLM's with large context lengths for best results.
LLM's have different context lengths that limit how much user data can be sent to them for processing. The current suite of tools don't provide any limitations on the length of user data that is sent to the LLM, so in some instances the LLM will throw an error saying the context limit size was reached.
A future enhancement would be to provide a configurable character limit for the user data tool responses. We accept PR's! :)
Centralized LLM services (OpenAI, Anthropic, Groq etc.) can access your prompts and any data sent to them.
Verida's API's operate within a secure, confidential compute, environment ensuring that user data is only exposed via the API requests with the permissions granted by a user.
When you connect a LLM to the Verida API's, the LLM can't access all the user data, but it can access any data response from the API's. For example; if you request a summary of your last 24 hours of emails, those emails will be sent to the LLM for processing, but the LLM can't automatically access all your emails.
This is very important to understand, because you are trusting these centralized LLM services to not expose your prompts or data sent to their LLM's. These could be exposed by malicious employees or as a result of a third party hack on that service.
There are two key ways you can eliminate the security risks associated with centralized LLM services:
Operate the LLM on a local device that you control
Use a LLM from a third party service that runs within a Trusted Execution Environment (TEE) such as Redpill AI (Very secure, but also very slow in our testing as of 26 Mar 2025).
Let’s dive deeper into how that would look, when addressing the top three data privacy issues.
Safeguarding privacy of user prompts has become an increasingly critical concern in the world of AI.
An end user can initiate a connection with a LLM hosted within a decentralized privacy-prserving compute engine called a Trusted Execution Environment (TEE), which provides a public encryption key. The end user encrypts their AI prompts using that public key and sends the encrypted prompts to the secure LLM.
Within this privacy-preserving environment, the encrypted prompts undergo decryption using a key only known by the TEE. This specialized infrastructure is designed to uphold the confidentiality and integrity of user data throughout the computation process.
Subsequently, the decrypted prompts are fed into the LLM for processing. The LLM generates responses based on the decrypted prompts without ever revealing the original, unencrypted input to any party beyond the authorized entities. This ensures that sensitive information remains confidential and inaccessible to any unauthorized parties, including the infrastructure owner.
By employing such privacy-preserving measures, users can engage with AI systems confidently, knowing that their data remains protected and their privacy upheld throughout the interaction. This approach not only enhances trust between users and AI systems but also aligns with evolving regulatory frameworks aimed at safeguarding personal data.
In a similar fashion, decentralized technology can be used to protect the privacy of custom-trained AI models that are leveraging proprietary data and sensitive information.
This starts with preparing and curating the training dataset in a manner that mitigates the risk of exposing sensitive information. Techniques such as data anonymization, differential privacy, and federated learning can be employed to anonymize or decentralize the data, thereby minimizing the potential for privacy breaches.
Next, an end user with a custom-trained Language Model (LLM) safeguards its privacy by encrypting the model before uploading it to a decentralized Trusted Execution Environment.
Once the encrypted custom-trained LLM is uploaded to the privacy-preserving compute engine, the infrastructure decrypts it using keys known only to TEE. This decryption process occurs within the secure confines of the compute engine, ensuring that the confidentiality of the model remains intact.
Throughout the training process, the privacy-preserving compute engine facilitates secure communication between the end user's infrastructure and any external parties involved in the training process, ensuring that sensitive data remains encrypted and confidential at all times. In a decentralized world, this data sharing infrastructure and communication will likely exist on a highly secure and fast protocol such as the Verida Network.
By adopting a privacy-preserving approach to model training, organizations can mitigate the risk of data breaches and unauthorized access while fostering trust among users and stakeholders. This commitment to privacy not only aligns with regulatory requirements but also reflects a dedication to ethical AI practices in an increasingly data-centric landscape.
AI models are only as good as the data they have access to. The vast majority of data is generated on behalf of, or by, individuals. This data is immensely valuable for training AI models, but must be protected at all costs due to its sensitivity.
End users can safeguard their private information by encrypting it into private training datasets before submission to a LLM training program. This process ensures that the underlying data remains confidential throughout the training phase.
Operating within a privacy-preserving compute engine, the LLM training program decrypts the encrypted training data for model training purposes while upholding the integrity and confidentiality of the original data. This approach mirrors the principles applied in safeguarding user prompts, wherein the privacy-preserving computation facilitates secure decryption and utilization of the data without exposing its contents to unauthorized parties.
By leveraging encrypted training data, organizations and individuals can harness the power of AI model training while mitigating the risks associated with data exposure. This approach enables the development of AI models tailored to specific use cases, such as utilizing personal health data to train LLMs for healthcare research applications or crafting hyper-personalized LLMs for individual use cases, such as digital AI assistants.
Following the completion of training, the resulting LLM holds valuable insights and capabilities derived from the encrypted training data, yet the original data remains confidential and undisclosed. This ensures that sensitive information remains protected, even as the AI model becomes operational and begins to deliver value.
To further bolster privacy and control over the trained LLM, organizations and individuals can leverage platforms like the Verida Network. Here, the trained model can be securely stored, initially under the private control of the end user who created it. Utilizing Verida's permission tools, users retain the ability to manage access to the LLM, granting permissions to other users as desired. Additionally, users may choose to monetize access to their trained models by charging others with crypto tokens for accessing and utilizing the model's capabilities.
api:connections-statusExample:
Full Documentation: Connections / Status
Credits Usage: 2 credits
Scope: api:llm-prompt
Response (example):
For full request/response structures and parameters, see the LLM Prompt Documentation.
Summary: Runs an LLM agent prompt that has access to user data. This allows you to leverage personal datastore or database records (based on your granted scopes) as context for the LLM, enabling personalized recommendations, summaries, or insights. This is avery intensive request as it can involve multiple LLM requests and multiple data queries.
Credits Usage: 5 credits
Scope Required: api:llm-agent-prompt
Response (example):
Note: The LLM agent uses the provided
contextto query datastores or databases your token is authorized to access. Ensure you request the necessary datastore or database scopes (e.g.,ds:r:fileor similar) alongsideapi:llm-agent-prompt.
For more advanced usage and available parameters, consult the LLM Agent Prompt Documentation.
Summary: Generates or refines a user profile by analyzing user data. Ideal for creating advanced personalized experiences, such as dynamic user profiles, recommendation engines, or curated content based on a user’s personal data footprint.
Credits Usage: 10 credits
Scope Required: api:llm-profile-prompt
Response (example):
Tip: Because
api:llm-profile-promptcan involve analyzing potentially large volumes of user data, it consumes more credits (10 credits). Make sure your token and user have granted the necessary access to the relevant datastores or databases.
For detailed query structures, limitations, and best practices, check the LLM Profile Prompt Documentation.
Minimal Scope Principle
Only request the LLM scope(s) you truly need. For instance, if you only require basic text generation, request api:llm-prompt rather than the more credit-expensive api:llm-agent-prompt or api:llm-profile-prompt.
Efficient Prompting Write concise prompts and consider the size of any included user context to avoid unnecessary token or data usage.
Store Results Securely If you need to retain LLM-generated data, store it in a datastore or database with the appropriate permissions.
Token & Scope Validation
Always confirm your auth_token includes the correct LLM scope before invoking these endpoints.
Handle Errors Gracefully LLM endpoints may return standard HTTP error codes or custom error messages. Review responses carefully and provide clear feedback to users if something goes wrong.
# dsUrlEncoded is typically the base64-encoded schema URL or a known shortcut
curl -X GET "https://api.verida.ai/api/rest/v1/connections/status" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN"# dsUrlEncoded is typically the base64-encoded schema URL or a known shortcut
curl -X GET "https://api.verida.ai/api/rest/v1/connections/profiles" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN"curl -X POST "https://api.verida.ai/api/rest/v1/llm/prompt" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"prompt": "Write a short poem about blockchain."
}'{
"completion": "Blockchain’s ledger forged in trust,\nWhere bits of code hold knowledge robust,\nConnecting minds across the globe,\nEmpowering dreams in digital robe."
}curl -X POST "https://api.verida.ai/api/rest/v1/llm/agent-prompt" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"prompt": "Summarize my recent meeting notes and suggest next steps.",
"context": {
"dsUrlEncoded": "aHR0cHM6Ly9jb21tb24uc2NoZW1hcy52ZXJpZGEuaW8vZmlsZS92MC4xLjAvc2NoZW1hLmpzb24=",
"queryFilters": { "meetingTopic": "Project Alpha" }
}
}'{
"completion": "Your recent meeting notes focus on Project Alpha’s roadmap. Key takeaways include ... Next recommended steps:..."
}curl -X POST "https://api.verida.ai/api/rest/v1/llm/profile-prompt" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"prompt": "Generate a professional summary and skill set based on user’s resume data.",
"context": {
"dsUrlEncoded": "aHR0cHM6Ly9jb21tb24uc2NoZW1hcy52ZXJpZGEuaW8vZmlsZS92MC4xLjAvc2NoZW1hLmpzb24=",
"queryFilters": { "documentType": "resume" }
}
}'{
"completion": "John is a full-stack developer with 5+ years experience in React, Node.js, and blockchain..."
}Run the Verida App Connect Example:
You can clone and run the Verida App Connect Example locally to test the authentication flow.
Inspect the source code to understand how authorization is integrated and how the auth_token is handled.
Generate an Auth Token from the :
Sign in to the Verida AI Developer Console and open the .
in the Sandbox for quick testing and to explore scopes.
Below is a typical flow when integrating your application with Verida AI:
Generate an authentication request URL
Include the scopes you require as well as the redirectUrl for successful authentication.
The easiest way to generate an authentication URL is via the Developer Sandbox and then edit the redirectUrl
Redirect the user to the authentication request URL
The user is prompted to grant or deny your application access.
User grants access and is redirected back
If the user grants access, they are redirected to your specified redirectUrl with an auth_token in the query parameters.
Store the auth_token
Your application should save the token securely, either linked to the user’s account in your database or in the user’s local browser storage.
Make requests to Verida APIs
Include the token in the Authorization header for all subsequent calls to Verida’s APIs.
You can embed a Connect button in your UI with the authentication URL as the link. When clicked, it sends users to the Verida authentication flow.
Replace ${authenticationURL} with the URL generated in the previous step.
Once the user grants your application access, they will be redirected to the redirectUrl you specified with an auth_token query parameter.
Example of how to capture the auth_token in TypeScript:
Explore Additional Scopes: Visit Verida’s Scopes API for a comprehensive list of available scopes.
Advanced Use Cases: Consider reading more about Verida’s data storage, encryption, and decentralized identity solutions to fully leverage the ecosystem.
Production Deployment: If you’re planning a production rollout, ensure you use secure storage for the auth_token.
These APIs enable developers to enable their third party applications to access the following services for a given Verida Account:
These APIs are currently read only, but will be expanded in the future to support:
Writing data
Accessing third party services (ie: send an email, order an Uber, send a Telegram message)
If you are familiar with Postman, you can load our pre-built Postman API's to easily access the Verida API's from your local machine.
You can obtain an auth token for a Verida account within the Developer Console and use the Sandbox to make API requests within your browser to learn how the various endpoints work with real data.
User data is "hot loaded" onto a confidential compute node on-demand. Within the secure enclave, user data is syncronized from the Verida network, decrypted and then loaded into memory for rapid access via API endpoints.
User data is then processed and made available in a variety of different ways:
Traditional database queries
Keyword search with ranking, filtering etc.
AI prompt with RAG access to user data
User Data remains in memory on the compute node while a user (or authorized application) is actively making API requests. If there are no requests for 30 minutes, the data in memory will be deleted and need to be hot-loaded again in the future.
Gmail
Google Calendar
Calendars
Events
Google Drive
Files
Youtube
Following
Likes
Subscriptions
Telegram
Groups
Messages
Notion
Slack
Fireflies
Spotify
You can view a list of completed, in progress and planned connectors in the Connectors Roadmap
Verida's Data Connections framework makes it easy for users to connect and pull their personal data from platforms like Google, Telegram, or Facebook into their private storage. The framework facilitates tasks like signing in, verifying access, and syncing user data from these centralized platforms.
The Verida Data Connection framework source code is open source and available on GitHub. A full list of connectors can be found in the providers folder.
Connections (ie: Google) have multiple handlers (ie: Gmail, Calendar etc.) that process different types of data available for a given connection. These handlers typically require specific permission to be granted when authorizing the connection. For example; A user will need to permit Verida access to the "Calendar" otherwise that data won't synchronize.
Handlers have built-in options specific to their functionality. For example; The Telegram handler has an option to only sync groups with less than 50 participants.
Handler options are currently implemented in the backend and will be made available in the user interface soon.
You can request a new connector via our roadmap here:
The default setting for all handlers is to fetch data up to 3 months old. In the future users will be able to customize this to increase the historical data to fetch. This will obviously increase the amount of data storage and memory usage for that user's data.
curl -X POST -H "Authorization: Bearer <authToken>" "https://api.verida.ai/api/rest/v1/llm/agent" \
-H "Content-Type: application/json" \
-d '{}'const axios = require('axios');
axios({
method: 'POST',
url: 'https://api.verida.ai/api/rest/v1/llm/agent',
data: {},
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer <authToken>'
}
})
.then(res => {
console.log(res.data)
})
.catch(err => {
console.error(err)
})const axios = require('axios');
const schemaUrl = 'https://common.schemas.verida.io/social/chat/group/v0.1.0/schema.json';
const schemaUrlEncoded = bvoa(schemaUrl);
axios({
method: 'POST',
url: `https://api.verida.ai/api/rest/v1/ds/query/${schemaUrlEncoded}`,
data: {
"options": {
"sort": [
{
"_id": "desc"
}
],
"limit": 20
}
},
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer <authToken>'
}
})
.then(res => {
console.log(res.data)
})
.catch(err => {
console.error(err)
})const axios = require('axios');
const schemaUrl = 'https://common.schemas.verida.io/social/chat/message/v0.1.0/schema.json';
const schemaUrlEncoded = bvoa(schemaUrl);
axios({
method: 'POST',
url: `https://api.verida.ai/api/rest/v1/ds/query/${schemaUrlEncoded}`,
data: {
"query": {
"sourceApplication": "https://telegram.com"
},
"options": {
"sort": [
{
"_id": "desc"
}
],
"limit": 20
}
},
headers: {
'Content-Type': 'application/json',
'Authorization': 'Bearer <authToken>'
}
})
.then(res => {
console.log(res.data)
})
.catch(err => {
console.error(err)
}){
"sourceApplication": "https://telegram.com",
"groupId": "telegram-456049390--579961374",
"type": "send",
"sentAt": {
"$gte": "2025-01-01"
}
}<a href="${authenticationURL}" id="connectButton" class="verida-connect">
<img src="https://assets.verida.io/auth/Connect-Verida.png" />
</a>const currentUrl = new URL(window.location.href);
const authToken = currentUrl.searchParams.get("auth_token");
if (authToken) {
// Save the token, e.g. in localStorage or your application database
localStorage.setItem("veridaAuthToken", authToken);
// You can now use this token to make requests to Verida APIs
}A breakdown on how to make personal data available for AI use cases
At Verida, We are working rapidly towards enabling personal data to be connected to AI for training and inference, in an end-to-end privacy preserving manner.
One of the questions to answer is how fast can data, stored in a decentralized database storage network like Verida, be made available to a personal AI agent. This is a critical question as huge time lags will create a poor user experience, making any personal AI products unviable.
There are many ways to use AI to communicate with data, however in this case we are assuming a Retrieval-Augmented Generation (RAG) approach.
The current architecture we are researching involves a “User Data API” that unlocks personal data stored (encrypted) on the Verida network, decrypts the data and then makes it available to AI agents and large language models (LLM’s) on demand.
This poses key latency questions:
What is the latency to fetch encrypted data from the network?
What is the latency to decrypt the data and make it queryable?
What is the latency to make the data searchable via Lucene style search queries?
While (3) isn’t absolutely necessary, at this stage it seems reasonable to assume a Lucene style search is a powerful tool to allow fast, flexible search queries across user data.
I used an early version of the () to pull my most recent 4,000 emails. This resulted in 250MB of raw database data (including PDF attachments converted to text), which became 330MB once database indexes were included.
I then ran the to hit the search endpoint that searches all my data matching the email schema (https://common.schemas.verida.io/social/email/v0.1.0/schema.json): http://localhost:5022/search/ds/aHR0cHM6Ly9jb21tb24uc2NoZW1hcy52ZXJpZGEuaW8vc29jaWFsL2VtYWlsL3YwLjEuMC9zY2hlbWEuanNvbg===?q=name:Luca
For testing purposes, the Personal Data Bridge and User Data API are running locally on my Macbook Pro. The Verida account is on the Banksia testnet, connected to a Storage Node running on my local machine.
Here’s the timed output from this initial set of tests:
Making a /search request involves the following time sensitive operations:
Time to sync encrypted user data from the Verida network to the local machine
Time to decrypt the user data into a decrypted database
Time to load all records from the decrypted database into memory
Time to load all data into an in memory Lucene index and query it
The screenshot shows three requests running over 4,000 of my personal emails.
Request 1
The first request took 3m 41s to complete steps 1,2,3.
Step 4 took an incredibly fast 38 ms.
Request 2
The second request used a cached copy of the Lucene index so only needed to complete step 4, again returning results in 38 ms.
Request 3
For the third request, I shut down the server, which cleared the in memory Lucene cache.
This request didn’t need to complete step 1. It completed steps 2 and 3 in 34s and generated the Lucene results in 26ms.
Note: Step 1 is actually pulling data from a Storage Node running on my local machine, not the network itself. As such step 1 is a bit faster than real world usage which would have this code running in data centres with fast pipes.
The baseline memory usage of the User Data API server is (bytes):
After loading the data in-memory (bytes):
This shows an increase in memory usage for the process from a baseline of 115MB to 772MB.
Here’s a breakdown of the learnings and a discussion on each.
It’s important to note that this infrastructure is intended to be run within secure enclaves to guarantee end-to-end privacy of user data. As it currently stands, secure enclaves only support in-memory storage, with no access to long term physical disk storage.
These are roughly extrapolated times for each step:
Step 1: Sync encrypted data: ~3 minutes
Step 2 & 3: Locally decrypt data and load into memory: ~34 seconds
Step 4: Load data into Lucene and run query: 34 milliseconds
The time to query the data is incredibly fast at 34ms, which is a huge positive.
However, the time to load the data in Step 1 is a blocker to a great user experience. That being said, this step only needs to occur once for any given server.
Under the Verida model of using decentralized identifiers, each Verida account will specify specific confidential compute nodes to act on their behalf. These nodes can sync this data once and then receive regular updates (using the Verida network real-time sync capabilities), keeping it up-to-date at all times.
The 34 seconds to decrypt and load into memory only needs to happen when the User Data API doesn’t have user data in it’s memory cache. This will happen when; 1) The server starts for the first time, or 2) If the cache is cleared (likely to happen after a period of inactivity for a user).
In reality, there may be a 30 second delay for this load process when a user makes their first request and then all subsequent requests should be very fast. Better hardware will drastically improve this load time.
Memory usage ballooned from 115MB to 772MB, an increase of 657MB. The raw uncompressed data (stored in memory database) was 330MB including indexes. 657MB is almost exactly 2x330MB which makes sense, because the data is actually loaded into memory twice. One copy is an in-memory database, the second copy is an in-memory Lucene database.
It’s quite possible the Lucene search service proves to be more useful than the in-memory database, allowing it to be dropped and halving that memory usage.
A future piece of work is to investigate running Lucene locally within the secure enclave, instead of storing in-memory. This would potentially eliminate the 30 second load time and significantly reduce the memory usage of the User Data API server.
Our vision is to enable AI to access all your digital data; email history, message history from chat platforms, search and browser history, health care data, financial records and more. That obviously requires a lot more than the 330MB of data used in this example.
The Personal Data Bridge supports pulling Facebook page likes and posts. I have pulled down over 3,000 facebook posts (excluding images and videos) which was less than 10MB.
We are still learning the volume of data for each dataset as we connect more sources to the Personal Data Bridge, but it’s probably safe to assume that email will be the largest data set for most people.
In my case 4,000 emails represented just 2 months of one of my multiple inboxes. The vast majority of those messages are junk / spam that I never intend to read. It may be sensible to add an additional processing layer over the data to eliminate emails that aren’t worth indexing. This will save memory and reduce time.
Extending that idea further, there will likely be a need to build additional metadata based on your personal data to help AI assistants to quickly know more about you. For example, you can enable a LLM to search your email and social media history to create a profile for you; age, gender, family, income, food preferences and much more. This is incredibly useful context to help guide any personal AI assistant, when combined with conducting real time search queries for specific prompts.
The current focus is getting an end-to-end solution that can be run on a local machine to connect your personal data to AI LLM’s.
While there are some performance bottlenecks mentioned above that could be investigated further, there is nothing that is an obvious blocker.
To that end, the next key priority is to be able to write a prompt (ie: Create a haiku of the conversation I had with my Mum about Mars) and have it sent to a locally running LLM (ie: Llama3) that has access to user data via the Lucene index to produce a meaningful result.
When a data source is connected, the data is transformed into a common data schema to provide consistency of the data, regardless of where it was sourced. For example a Facebook post and an X post will both be transformed into a common social post record, matching the social post schema.
Description: A social media post
Link:
Data sources: X (Twitter), Facebook
Description: An account the user is following
Link:
Data sources: Youtube, Discord, Facebook, X
Description: A favourite of the user (ie: Liked Youtube video)
Link:
Data sources: Youtube
Description: An email
Link:
Data sources: X (Twitter), Facebook
Description: A file. Note: Files on third party platforms are typically not stored, rather linked to (ie: Google Doc link)
Link:
Data sources: Google Drive, User uploads via Verida Vault web interface
Description: A chat group
Link:
Data sources: Telegram
Description: A chat message
Link:
Data sources: Telegram
Description: A calendar
Link:
Data sources: Google Calendar
Description: An event within a calendar
Link:
Data sources: Google Calendar

{
"rss": 115982336,
"heapTotal": 36827136,
"heapUsed": 33001104,
"external": 2117266,
"arrayBuffers": 54788
}{
"rss": 772591616,
"heapTotal": 362926080,
"heapUsed": 351119608,
"external": 2156712,
"arrayBuffers": 82355
}

Verida offers a suite of Query APIs that enable you to store, query, and manage user data across decentralized databases and datastores, as well as perform advanced searches. This page covers the Databases and Datastores sections of the Verida User API Reference.
For full technical details, consult the Verida API Reference Documentation.
Datastores
Get a Record by ID (api:ds-get-by-id)
Create a Record (api:ds-create)
Update a Record (api:ds-update)
Databases
Get a Record by ID (api:db-get-by-id)
Create a Record (api:db-create)
Update a Record (
Datastores are schema-based collections of structured data. Endpoints for datastores operate similarly to databases but typically refer to a base64-encoded schema URL or a well-known shortcut. Each datastore endpoint requires the relevant API scope (e.g., api:ds-get-by-id) and uses 1 credit per request unless otherwise noted.
HTTP Method & Endpoint: GET /ds/{dsUrlEncoded}/{id}
Summary: Retrieve a specific record by its id from a datastore.
Credit Usage: 1 credit
HTTP Method & Endpoint: POST /ds/{dsUrlEncoded}
Summary: Insert a new record into the specified datastore.
Credit Usage: 1 credit
Scope:
HTTP Method & Endpoint: PUT /ds/{dsUrlEncoded}/{id}
Summary: Update an existing datastore record identified by id.
Credit Usage: 1 credit
HTTP Method & Endpoint: POST /ds/query/{dsUrlEncoded}
Summary: Run queries (similar to databases) from a datastore.
Credit Usage: 1 credit
Scope:
HTTP Method & Endpoint: POST /ds/count/{dsUrlEncoded}
Summary: Count the number of results in a datastore that match a query
Credit Usage: 0 credits
Scope:
HTTP Method & Endpoint: GET /ds/watch/{dsUrlEncoded}
Summary: Subscribe to real-time updates from a datastore. This is not a typical HTTP request, it uses EventSource to stream the database changes.
Credit Usage: 1 credit
HTTP Method & Endpoint: DELETE /ds/{dsUrlEncoded}/{id}
Summary: Remove a record permanently from a datastore.
Credit Usage: 1 credit
Scope:
Database endpoints allow you to work with traditional, table-like data. Each endpoint requires an auth_token with the relevant API scope (e.g., api:db-get-by-id) and consumes 1 credit per request unless otherwise noted.
HTTP Method & Endpoint: GET /db/{dbName}/{id}
Summary: Fetch a single record from a specific database using its unique id.
Credit Usage: 1 credit
HTTP Method & Endpoint: POST /db/{dbName}
Summary: Insert a new record into the specified database.
Credit Usage: 1 credit
Scope:
HTTP Method & Endpoint: PUT /db/{dbName}/{id}
Summary: Modify an existing record identified by id in a specific database.
Credit Usage: 1 credit
HTTP Method & Endpoint: POST /db/query/{dbName}
Summary: Run queries to filter and retrieve multiple records from the specified database.
Credit Usage: 1 credit
HTTP Method & Endpoint: POST /db/count/{dbName}
Summary: Count the number of results in a database that match a query
Credit Usage: 0 credits
Scope:
Secure Your Requests: Always include the Authorization: Bearer YOUR_AUTH_TOKEN header and ensure your application only requests the necessary scopes.
Understand Credit Costs: Each API call draws from your available credits. Optimize your queries and reduce unnecessary calls.
Use the Right Endpoint: Databases vs. Datastores have subtle differences. Identify which storage mechanism and endpoint best suit your application.
Get started by building a new API Connector
We actively encourage the development of any new data providers that expand the available API's users can connect to pull their personal data.
You can browse the open issues for new connectors.
Key terms:
Provider: A data provider object (ie: facebook) that manages a user authenticating with the provider to establish a connection.
Connection: A specific connection that a user has made with a provider. Connections are stored in a user's Verida Vault.
Handler: Providers have multiple handlers (ie: the google provider has handlers gmail, youtube) that manage specific configuration options and performs the necessary syncronization
Schema: Syncronized data must be mapped to a relevant schema, for instance the syncronizes data to the . The file lists the standard schemas.
You will need to first setup your environment by running the on your local machine:
You will need to update your local configuration variables:
accessCheckEnabled: false
testVeridaKey: Create a new Verida account using the Verida Wallet
And then start the server:
You can now open the developer admin interface at .
A data connector is made up of the core providerclass and then one or more handlerclasses. For example, for Google we have a and then a , , etc.
It's strongly recommended to copy an existing connector as a starting point and then update the authentication and API code to suit your new connector. Similarly, it's strongly recommended to copy an existing handler that matches the data schema you are populating. ie: If it's a social media platform and you are saving social media posts, start with the .
Here are the key steps for implementing your provider class:
Create src/providers/<provider-name>/index.ts extending
Create assets/<provider-name>/icon.png with the official icon for the data connector. Must be 256x256 pixels.
Create an exported Typescript interface called ConfigInterface that defines the configuration options available for the API.
Other considerations:
The authentication must use passport-js if an existing authentication module exists.
The official npm package of the API in question must be used if it exists.
There should be no console output, instead use log4js with sensible logging (trace, debug, info
The data source handler must populate the appropriate schema with relant fields sourced from the API. Each handler typically is responsible for one data schema. There are exceptions to this rule, for example a chat application where a handler may populate the chat group and the chat messageschemas in the one handler.
While the fields may vary, at a minimum the handler must populate the following fields:
_id - A unique ID of this record that includes the provider name, profile identifier and the item identifier. This guarantees uniqueness even if the user connects the same source twice. Use Handler.buildItemId(itemId: string) to build the _id correctly.
name - A human readable name that best represents the record
sourceApplication
Some common optional fields include:
uri - A URL to view the pi
icon - A small icon representing the data
summary - A brief summary of the recrod
It's essential handlers catch any errors relating to token expiry and handles them appropriately:
Expired access token, refresh token available. Obtain a new access token and call provider.updateConnection() to set the new access token, which will then be automatically saved
Expired refresh token. Throw a TokenExpiredError()
You must create an entry in for the provider that provides the default configuration for the data connector.
Your connector and handlers must track the progress of the sync to ensure that if something goes wrong or the sync is stopped for any reason, it can pickup where it left off without any issues.
Typically the sync does the following:
Does an initial sync of all available data
Does a catch-up sync of new data
The sync process should always sync in batches, with a configurable batch size, to allow the sync manager to start / stop the sync as required.
There is an used by many of the existing handlers. This class is designed to track the sync progress within a known set of record identifiers (or timestamps). It supports importing the current sync position from a saved string in the user's database, and exporting the current sync position for saving in the user's database.
It supports updateRangeand completedRangemethods that update the sync status when a range of records has completed processing.
Handlers can provide configurable options that a user can modify. For example, the allows a user to specify what types of chat messages are syncronized (ie: Private, Secret, Basic etc.).
Ensure your handler specfies appropriate default values for all options as there is the user interface for users to select these options is not yet available.
When building your own connector, it can be very helpful to use the command line tools to connect your new provider, manually sync data, reset your connector and show data that has syncronized.
View all available commands:
Outputs:
You must implement unit tests in the director /test/<provider-name>/<handler-name>.ts file that contains appropriate unit tests that demonstrates successful fetching of data, successful handling of API errors and any other relevant edge cases.
When running the tests, you will need to ensure your serverconfig.local.config has verida.testVeridaKeyset with the seed phrase of a Verida Account that will be storing your user data.
Your test Verida Account may have multiple connections to the same provider. In that case you can specify a specific providerId when running unit tests --providerId=<12345> .
Each data source provider must contain the following:
src/providers/<provider-name>/README.md containing:
Instructions on how to obtain any necessary API keys for the server
Instructions on how to configure the provider
Any limitations of the provider (ie: Only fetches maximum of 1,000 records)

api:ds-query)Count records (api:ds-query)
Watch a Datastore (api:ds-query)
Delete a Record (api:ds-delete)
api:db-updateQuery a Database (api:db-query)
Count records (api:db-query)
api:ds-get-by-idExample:
Full Documentation: Datastore: Get Record by ID
api:ds-createExample:
Full Documentation: Datastore: Create Record
api:ds-updateExample:
Full Documentation: Datastore: Update Record
api:ds-queryExample (Query):
Full Documentation: Datastore: Query
api:ds-queryExample (Query):
Full Documentation: Datastore Count
api:ds-queryFull Documentation: Datastore: Watch
api:ds-deleteExample:
api:db-get-by-idExample:
Full Documentation: Database: Get Record by ID
api:db-createExample:
api:db-updateExample:
api:db-queryExample:
Full Documentation: Database: Query
api:db-queryExample:
Full Documentation: Database: Query
GET /ds/watch) to keep application data in sync without continuous polling.Respect Scope Requirements: For instance, if you need api:ds-delete, your user must grant a scope that allows delete access (e.g., ds:rwd:file).
errorUse appropriate Verida data schemas if they exist (see list in serverconfig.example.json).
Do NOT commit a PR with any API keys, accessTokens or other secrets!
wwwhttpssourceId - Unique ID of the record sourced from the API
sourceData - Full, unaltered JSON of the data retreived from the API. This allows a future upgrade path to add more data into the schema from the original data.
insertedAt - Date/time the data was inserted. If not available in the API, use another date/time that is an approximation, or worst case scenario use the current date/time.
uri - A public link to the unique record in the application (ie: Tweet URL) Token Expiry / Refresh TokensAny issues where the data provided doesn't exactly match the schema
Details of any new schemas created to support this API connector or modifications to existing schemas (including a link to a PR that contains the proposed schema changes in the @verida/schemas-common repo)
Details of any future improvements or features that could be considered
Details of any performance considerations
Details of any known issues with the data source API being used
# dsUrlEncoded is typically the base64-encoded schema URL or a known shortcut
curl -X GET "https://api.verida.ai/api/rest/v1/ds/aHR0cHM6Ly9....json/456" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN"curl -X POST "https://api.verida.ai/api/rest/v1/ds/aHR0cHM6Ly9.../" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"key": "value",
"createdAt": "2025-02-03T12:00:00Z"
}'curl -X PUT "https://api.verida.ai/api/rest/v1/ds/aHR0cHM6Ly9.../456" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"updatedKey": "newValue"
}'curl -X POST "https://api.verida.ai/api/rest/v1/ds/query/aHR0cHM6Ly9..." \
-H "Authorization: Bearer YOUR_AUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"filters": { "key": "value" }
}'curl -X POST "https://api.verida.ai/api/rest/v1/ds/count/aHR0cHM6Ly9..." \
-H "Authorization: Bearer YOUR_AUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"filters": { "key": "value" }
}'curl -X DELETE "https://api.verida.ai/api/rest/v1/ds/aHR0cHM6Ly9.../456" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN"curl -X GET "https://api.verida.ai/api/rest/v1/db/myDatabase/123" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN"curl -X POST "https://api.verida.ai/api/rest/v1/db/myDatabase" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"title": "First Entry",
"content": "Hello World!"
}'curl -X PUT "https://api.verida.ai/api/rest/v1/db/myDatabase/123" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"title": "Updated Title",
"content": "Revised Content"
}'curl -X POST "https://api.verida.ai/api/rest/v1/db/query/myDatabase" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"filters": { "status": "active" },
"limit": 10
}'curl -X POST "https://api.verida.ai/api/rest/v1/db/count/myDatabase" \
-H "Authorization: Bearer YOUR_AUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"filters": { "status": "active" },
"limit": 10
}'git clone https://github.com/verida/data-connector-server.git
cd data-connector-server
yarn
cp serverconfig.example.json serverconfig.local.jsonyarn run devyarn run cli --helpCommands
Connect Connect to a third party data provider and save the credentials into
the Verida: Vault context
Sync Sync to a third party data provider and save the credentials into the
Verida: Vault context
Data Show data for a given schema
ResetProvider Clear all the data and reset sync positions for a provider
Connections Show data for a given schema{
"_id": "telegram-456049390-969538878",
"sourceApplication": "https://telegram.com",
"sourceId": "969538878",
"sourceData": {
"_": "chat",
"id": 969538878,
"type": {
"_": "chatTypePrivate",
"user_id": 969538878
},
"title": "",
"accent_color_id": 0,
"background_custom_emoji_id": "0",
"profile_accent_color_id": -1,
"profile_background_custom_emoji_id": "0",
"permissions": {
"_": "chatPermissions",
"can_send_basic_messages": true,
"can_send_audios": true,
"can_send_documents": true,
"can_send_photos": true,
"can_send_videos": true,
"can_send_video_notes": true,
"can_send_voice_notes": true,
"can_send_polls": true,
"can_send_other_messages": true,
"can_add_link_previews": true,
"can_change_info": false,
"can_invite_users": false,
"can_pin_messages": true,
"can_create_topics": false
},
"last_message": {
"_": "message",
"id": 73545023488,
"sender_id": {
"_": "messageSenderUser",
"user_id": 969538878
},
"chat_id": 969538878,
"is_outgoing": false,
"is_pinned": false,
"is_from_offline": false,
"can_be_saved": true,
"has_timestamped_media": true,
"is_channel_post": false,
"is_topic_message": false,
"contains_unread_mention": false,
"date": 1733217396,
"edit_date": 0,
"unread_reactions": [],
"message_thread_id": 0,
"saved_messages_topic_id": 0,
"self_destruct_in": 0,
"auto_delete_in": 0,
"via_bot_user_id": 0,
"sender_business_bot_user_id": 0,
"sender_boost_count": 0,
"author_signature": "",
"media_album_id": "0",
"effect_id": "0",
"has_sensitive_content": false,
"restriction_reason": "",
"content": {
"_": "messageText",
"text": {
"_": "formattedText",
"text": "Hey good day. I am a marketing manager and content producer on YouTube.",
"entities": [
{
"_": "textEntity",
"offset": 264,
"length": 29,
"type": {
"_": "textEntityTypeUrl"
}
},
{
"_": "textEntity",
"offset": 295,
"length": 25,
"type": {
"_": "textEntityTypeUrl"
}
}
]
},
"link_preview": {
"_": "linkPreview",
"url": "http://www.youtube.com/@NewCrypto",
"display_url": "youtube.com/channel/...",
"site_name": "YouTube",
"title": "New Crypto",
"description": {
"_": "formattedText",
"text": "🤙 Hello welcome to my channel I'm New Crypto",
"entities": [
{
"_": "textEntity",
"offset": 419,
"length": 27,
"type": {
"_": "textEntityTypeUrl"
}
},
{
"_": "textEntity",
"offset": 454,
"length": 22,
"type": {
"_": "textEntityTypeEmailAddress"
}
},
{
"_": "textEntity",
"offset": 483,
"length": 24,
"type": {
"_": "textEntityTypeEmailAddress"
}
}
]
},
"author": "",
"type": {
"_": "linkPreviewTypePhoto",
"photo": {
"_": "photo",
"has_stickers": false,
"minithumbnail": {
"_": "minithumbnail",
"width": 40,
"height": 40,
"data": "/9j/4AAQSk...//Z"
},
"sizes": [
{
"_": "photoSize",
"type": "m",
"photo": {
"_": "file",
"id": 2540,
"size": 20616,
"expected_size": 20616,
"local": {
"_": "localFile",
"path": "",
"can_be_downloaded": true,
"can_be_deleted": false,
"is_downloading_active": false,
"is_downloading_completed": false,
"download_offset": 0,
"downloaded_prefix_size": 0,
"downloaded_size": 0
},
"remote": {
"_": "remoteFile",
"id": "Ag...gQ",
"unique_id": "AQADxrUxG4eqhVNy",
"is_uploading_active": false,
"is_uploading_completed": true,
"uploaded_size": 20616
}
},
"width": 320,
"height": 320,
"progressive_sizes": []
},
{
"_": "photoSize",
"type": "x",
"photo": {
"_": "file",
"id": 2541,
"size": 83116,
"expected_size": 83116,
"local": {
"_": "localFile",
"path": "",
"can_be_downloaded": true,
"can_be_deleted": false,
"is_downloading_active": false,
"is_downloading_completed": false,
"download_offset": 0,
"downloaded_prefix_size": 0,
"downloaded_size": 0
},
"remote": {
"_": "remoteFile",
"id": "AgACA...NgQ",
"unique_id": "AQADxrUxG4eqhVN9",
"is_uploading_active": false,
"is_uploading_completed": true,
"uploaded_size": 83116
}
},
"width": 800,
"height": 800,
"progressive_sizes": []
},
{
"_": "photoSize",
"type": "y",
"photo": {
"_": "file",
"id": 2542,
"size": 92438,
"expected_size": 92438,
"local": {
"_": "localFile",
"path": "",
"can_be_downloaded": true,
"can_be_deleted": false,
"is_downloading_active": false,
"is_downloading_completed": false,
"download_offset": 0,
"downloaded_prefix_size": 0,
"downloaded_size": 0
},
"remote": {
"_": "remoteFile",
"id": "AgACA....DNgQ",
"unique_id": "AQADxrUxG4eqhVN-",
"is_uploading_active": false,
"is_uploading_completed": true,
"uploaded_size": 92438
}
},
"width": 900,
"height": 900,
"progressive_sizes": [
11770,
26273,
37932,
55019
]
}
]
}
},
"has_large_media": true,
"show_large_media": false,
"show_media_above_description": false,
"skip_confirmation": true,
"show_above_text": false,
"instant_view_version": 0
}
}
},
"positions": [
{
"_": "chatPosition",
"list": {
"_": "chatListMain"
},
"order": "7444112032678351354",
"is_pinned": false
}
],
"chat_lists": [
{
"_": "chatListMain"
}
],
"has_protected_content": false,
"is_translatable": true,
"is_marked_as_unread": false,
"view_as_topics": false,
"has_scheduled_messages": false,
"can_be_deleted_only_for_self": true,
"can_be_deleted_for_all_users": false,
"can_be_reported": false,
"default_disable_notification": false,
"unread_count": 0,
"last_read_inbox_message_id": 73545023488,
"last_read_outbox_message_id": 0,
"unread_mention_count": 0,
"unread_reaction_count": 0,
"notification_settings": {
"_": "chatNotificationSettings",
"use_default_mute_for": true,
"mute_for": 0,
"use_default_sound": true,
"sound_id": "-1",
"use_default_show_preview": true,
"show_preview": false,
"use_default_mute_stories": true,
"mute_stories": false,
"use_default_story_sound": true,
"story_sound_id": "-1",
"use_default_show_story_sender": true,
"show_story_sender": true,
"use_default_disable_pinned_message_notifications": true,
"disable_pinned_message_notifications": false,
"use_default_disable_mention_notifications": true,
"disable_mention_notifications": false
},
"available_reactions": {
"_": "chatAvailableReactionsAll",
"max_reaction_count": 11
},
"message_auto_delete_time": 0,
"theme_name": "",
"video_chat": {
"_": "videoChat",
"group_call_id": 0,
"has_participants": false
},
"reply_markup_message_id": 0,
"client_data": ""
},
"schema": "https://common.schemas.verida.io/social/chat/group/v0.1.0/schema.json",
"name": "New Crypto",
"insertedAt": "2025-02-19T17:36:43.727Z",
"newestId": "telegram-456049390-73545023488",
"syncData": "[[\"73545023488\",\"73545023488\"]]",
"_rev": "417-d41b598b5826c16d1f5cc85249740721",
"modifiedAt": "2025-02-19T17:37:43.122Z",
"signatures": {
"did:vda:mainnet:0xa603b7b8af20c9a73329a165666520be27fe0c4c2?context=0xb3c1545890d337d6f281177e5e0d3c3ac5d3308a1d696022d907c0b514f87bf4": {
"secp256k1": "0xbb5541cab6411ca1106fdf0e35894d1f5f15b35e713369c1d5a3037c7e243fa14426dbd9ae987fb5f92b60fd58446bfb1a985f5ef69ec1ef24eebf06146453171b"
}
}
}{
"_id": "telegram-456049390-9997123584",
"name": "Has the next API vers...",
"groupId": "telegram-456049390--579961374",
"groupName": "Verida Team",
"type": "receive",
"fromId": "225312638",
"fromHandle": "StevieBlank",
"fromName": "StevieBlank",
"messageText": "Has the next API version been released yet?",
"schema": "https://common.schemas.verida.io/social/chat/message/v0.1.0/schema.json",
"sourceApplication": "https://telegram.com",
"sourceId": "9997123584",
"sourceData": {
"_": "message",
"id": 9997123584,
"sender_id": {
"_": "messageSenderUser",
"user_id": 215312638
},
"chat_id": -579961374,
"is_outgoing": false,
"is_pinned": false,
"is_from_offline": false,
"can_be_saved": true,
"has_timestamped_media": true,
"is_channel_post": false,
"is_topic_message": false,
"contains_unread_mention": false,
"date": 1618537454,
"edit_date": 0,
"unread_reactions": [],
"message_thread_id": 0,
"saved_messages_topic_id": 0,
"self_destruct_in": 0,
"auto_delete_in": 0,
"via_bot_user_id": 0,
"sender_business_bot_user_id": 0,
"sender_boost_count": 0,
"author_signature": "",
"media_album_id": "0",
"effect_id": "0",
"has_sensitive_content": false,
"restriction_reason": "",
"content": {
"_": "messageText",
"text": {
"_": "formattedText",
"text": "Has the next API version been released yet?",
"entities": []
}
}
},
"insertedAt": "2021-04-16T01:44:14.000Z",
"sentAt": "2021-04-16T01:44:14.000Z",
"modifiedAt": "2025-02-10T09:59:54.568Z",
"signatures": {
"did:vda:mainnet:0x1a4a7b8af20c9a73329a165666520be27fe0c4c2?context=0xb3c1545890d337d6f281177e5e0d3c3ac5d3308a1d696022d907c0b514f87bf4": {
"secp256k1": "0xfb188241fc25c10b819dd105a0126e66de8b9b12765254f30bb08167a1c8eb1317138cca8f39cff458c4c096bbf800c45d426a2abcbba82358c11b64c8d9d0311c"
}
},
"_rev": "1-8315fdd91bc77906ff7d876c856ebd08"
}Learn about all the available scopes for accessing user data
Verida provides a robust and granular permission model to control access to user data and APIs. This document summarizes all available scopes, how they are organized, and how to use them in your application.
There are three main categories of scopes:
API Scopes (api:)
Provide access to specific Verida API endpoints (e.g., LLM prompts, universal search).
Database Scopes (db:)
Grant read, write, and delete access to a specific database within Verida.
Datastore Scopes (ds:)
Grant read, write, and delete access to a specific datastore (structured data) within Verida.
API scopes provide access to particular operations or specialized APIs within the Verida ecosystem. These scopes have a number of credits that are consumed when these API endpoints are invoked.
Below is a breakdown by functionality:
api:llm-prompt
Allows running a Large Language Model (LLM) prompt without access to user data.
api:llm-agent-prompt
Allows running a Large Language Model agent prompt with access to user data.
api:llm-profile-prompt
Allows running an LLM prompt to generate a profile based on user data
api:search-universal
Perform a keyword-based search across all user data.
api:search-ds
Perform a keyword-based search across a specific datastore.
api:search-chat-threads
Perform a keyword-based search across all chat threads.
api:db-get-by-id
Endpoint: GET /db/$dbName/$id
Allows retrieving a record by ID from a specific database.
api:ds-get-by-id
Endpoint: GET /ds/$dsUrlEncoded/$id
Retrieve a record by ID from a specific datastore.
db:)When requesting database-level access, your application must specify the permission type and the database name. The permissions are:
r: Read-only
rw: Read and write
rwd: Read, write, and delete
A typical database scope looks like:
For example:
db:r:file
Read-only access to the file database.
db:rw:file
Note: The
dbNameoften corresponds to an internal Verida database identifier (e.g.,file), but it can vary depending on the specific database you want to access.
ds:)Similar to databases, datastore scopes define the level of access to structured data by referencing a schema URL (or a short-hand for common schemas). Permissions mirror database scopes:
r: Read-only
rw: Read and write
rwd: Read, write, and delete
where:
base64EncodedSchemaUrl is the base64-encoded URL of the datastore schema, or a short-hand if it’s a well-known schema.
For example, the Files datastore schema:
Base64-encoded, it might look like:
Hence, read-only scope for that datastore:
Tip: You can generate base64 values using:
btoa()in the browser
Buffer.from("http://...").toString("base64")in Node/TypeScript
Verida provides short-hand references for commonly used datastores. In these cases, you can simply specify the short name instead of the base64-encoded URL. For instance:
Examples with Shortcuts
ds:r:file
Read-only access to the Files datastore.
ds:rw:social-following
Read and write access to the Social Following datastore.
ds:rwd:social-event
Read, write, and delete access to the Social Event datastore.
Below is a combined list of all scopes you may encounter or request:
LLM Scopes
api:llm-prompt
api:llm-agent-prompt
db:)db:r:{databaseName}
db:rw:{databaseName}
db:rwd:{databaseName}
Examples:
db:r:file
db:rw:file
db:rwd:file
ds:)ds:r:{datastoreShortcutOrBase64Url}
ds:rw:{datastoreShortcutOrBase64Url}
ds:rwd:{datastoreShortcutOrBase64Url}
Common shortcuts include:
social-following, social-post, social-email, favourite, file, social-chat-group, social-chat-message, social-calendar, social-event
Examples:
ds:r:file
ds:rw:social-post
ds:rwd:social-event
Request Only Needed Scopes
Align the scopes with the data and endpoints your application genuinely requires. Minimizing scopes reduces security risks and simplifies user acceptance.
Explain Scopes to Users
Scopes API: Fetch a real-time list of valid scopes, including new or updated scopes.
Developer Console: An easy to use interface to generate authorization requests and use APIs.
Verida GitHub: Explore sample applications and open-source libraries.
By combining these scopes effectively, you can harness the power of Verida’s decentralized data ecosystem while respecting user consent and data security.
api:db-createEndpoint: POST /db/$dbName
Allows creating a new record in a specific database.
api:db-update
Endpoint: PUT /db/$dbName/$id
Allows updating an existing record in a specific database.
api:db-query
Endpoint: POST /db/query/$dbName
Allows querying a specific database.
api:ds-createEndpoint: POST /ds/$dsUrlEncoded
Create a new record in a specific datastore.
api:ds-update
Endpoint: PUT /ds/$dsUrlEncoded/$id
Update an existing record in a specific datastore.
api:ds-query
Endpoints:
POST /ds/query/$dsUrlEncoded (query a datastore)
GET /ds/watch/$dsUrlEncoded (subscribe to datastore changes)
Query or watch a specific datastore.
api:ds-delete
Endpoint: DELETE /ds/$dsUrlEncoded/$id
Delete a record from a specific datastore.
Read and write access to the file database.
db:rwd:file
Read, write, and delete access to the file database.
social-chat-message
Chat messages (e.g., Telegram messages)
social-calendar
Calendars (e.g., Personal Google Calendar)
social-event
Calendar events (e.g., Meeting with Jane)
api:llm-profile-promptSearch Scopes
api:search-universal
api:search-ds
api:search-chat-threads
Database API
api:db-get-by-id
api:db-create
api:db-update
api:db-query
Datastore API
api:ds-get-by-id
api:ds-create
api:ds-update
api:ds-query
api:ds-delete
ds:r:base64/aHR0cHM6Ly9jb21tb24u...Store Tokens Securely
Whether you are using a database or localStorage, always handle tokens and granted scopes in a secure manner.
Check for Scope Changes
The Verida ecosystem may add or update scopes. Always verify the latest scope list from the Scopes API or developer documentation.
social-following
Social media following (e.g., Facebook pages)
social-post
Social media posts
social-email
Emails
favourite
Favourites (e.g., liked videos, bookmarks)
file
Files (e.g., documents)
social-chat-group
Chat groups (e.g., Telegram groups)
cssCopydb:{permission}:{databaseName}ds:{permission}:{base64EncodedSchemaUrl}https://common.schemas.verida.io/file/v0.1.0/schema.jsonaHR0cHM6Ly9jb21tb24uc2NoZW1hcy52ZXJpZGEuaW8vZmlsZS92MC4xLjAvc2NoZW1hLmpzb24=ds:r:base64/aHR0cHM6Ly9jb21tb24uc2NoZW1hcy52ZXJpZGEuaW8vZmlsZS92MC4xLjAvc2NoZW1hLmpzb24=Verida’s mission has always been clear: empower individuals to own and control their data. Now, we’re taking it further.
This Technical Litepaper presents a high-level outline of how the Verida Network is growing beyond decentralized, privacy preserving databases, to support decentralized, privacy-preserving compute optimized for handling private data. There are numerous privacy issues currently facing AI that web3 and decentralized physical infrastructure networks can help solve. From Verida’s perspective, this represents an expansion of our mission from allowing individuals to control their data to introducing new and powerful ways for users to benefit from their data.
We are running out of high-quality data to train LLMs
Public internet data has been scraped and indexed by AI models, with researchers estimating that by 2026, we will exhaust high-quality text data for training LLMs. Next, we need to access private data, but it’s hard and expensive to access.
Private enterprise and personal AI agents need to access private data
There is a lot of excitement around the next phase of AI beyond chat prompts. Digital twins or personal AI agents that know everything about us and support every aspect of our professional and personal lives. However, to make this a reality AI models need access to private, real time context-level user data to deliver more powerful insights and a truly personalized experience.
Existing AI platforms are not private
The mainstream infrastructure providers powering the current generation of AI products have full access to prompts and training data, putting sensitive information at risk.
AI trust and transparency is a challenge
Regulation is coming to AI and it will become essential that AI models can prove the training data was high quality, ethically sourced. This is critical to reduce bias, misuse and improve safety in AI.
Data creators aren’t being rewarded
User-owned data is a critical and valuable resource for AI and those who create the data should benefit from its use. Reddit recently sold user data for $200M, while other organizations have reached similar agreements. Meta is training its AI models on user data from some countries, but excluding European users due to GDPR preventing them from doing so without user consent.
Verida has already developed the leading private decentralized database storage infrastructure (see Verida Whitepaper) which provides a solid foundation to address the current AI data challenges.
Expanding the Verida network to support privacy-preserving compute enables private, encrypted data to be integrated with leading AI models, ensuring end-to-end privacy, safeguarding data from model owners. This will unlock a new era of hyper-personal and safe AI experiences.
AI services such as ChatGPT have full access to any information users supply and have already been known to leak sensitive data. By enabling model owners access to private data, there is increased risks of data breaches, imperiling privacy, and ultimately limiting AI use cases.
There are three key problems Verida is solving to support secure private AI:
Data Access: Enabling users to extract and store their private data from third party platforms for use with emerging AI prompts and agents.
Private Storage and Sharing: Providing secure infrastructure allowing user data to be discoverable, searchable and accessible with user-consent to third party AI platforms operating within verifiable confidential compute environments.
Private Compute: Provide a verifiable, confidential compute infrastructure enabling agentic AI computation to securely occur on sensitive user data.
Supporting the above tasks, Verida is building a “Private Data Bridge”, allowing users to reclaim their data and use it within a new cohort of personalized AI applications. Users can pull their private data from platforms such as Google, Slack, Notion, email providers, LinkedIn, Amazon, Strava, and much more. This data is encrypted and stored in a user-controlled private data Vault on the Verida network.
It’s important to note that Verida is not building infrastructure for decentralized AI model training, or distributed AI inference. Rather, Verida’s focus is on providing a high performance, secure, trusted and verifiable infrastructure suitable for managing private data appropriate for AI use cases.
We have relationships with third parties that are building; private AI agents, AI data marketplaces and other privacy-centric AI use cases.
AI solutions can be deployed primarily through two methods: cloud-based/hosted services or on local machines.
Cloud-based AI services, while convenient and scalable, expose sensitive user data to potential risks, as data processing occurs on external servers and may be accessible to third parties.
In contrast, local AI environments offer enhanced security, ensuring that user data remains isolated and inaccessible to other applications or external entities. However, local environments come with significant limitations, including the need for technical expertise that is not available to the majority of users. Moreover, these environments often face performance challenges; for instance, running large language models (LLMs) on standard consumer hardware is typically impractical due to the high computational demands.
Verida’s Confidential Storage and Compute infrastructure offers alternatives to these approaches.
Apple has recently announced Private Cloud Compute that provides a hybrid local + secure cloud approach. AI processing occurs on a local device (ie: mobile phone) by default, then when additional processing power is required, the request is offloaded to Apple’s servers that are operating within a trusted execution environment. This is an impressive offering that is focused on solving important security concerns relating to user data and AI. However, it is centralized, only available to Apple devices and puts significant trust in Apple as they control both the hardware and attestation keys.
Let’s look at what an ideal model of confidential AI architecture looks like. This is an interaction model of how a basic “Self-Sovereign AI” chat interface, using a RAG-style approach, would operate in an end-to-end confidential manner.
The End User Application in this example will be a “Chat Prompt” application. A user enters a prompt (i.e., “Summarize the conversation I had with my mates about the upcoming golf trip”).
A Private AI API endpoint (AI Prompt) receives the chat prompt and breaks down the request. It sends a prompt to the LLM, converting the original prompt into a series of search queries. The LLM could be an open source or proprietary model. Due to the confidential nature of the secure enclave, proprietary models could be deployed without risk of IP theft by the model owner.
The search queries are sent to the User Data API which has access to data previously obtained via Verida’s Private Data Bridge. This data includes emails, chat message histories and much more.
The Private AI API collates the search query results and sends the relevant responses and original prompt to the LLM to produce a final result that is returned to the user.
Verida is currently developing a “showcase” AI agent that implements this architecture and can provide a starting point for other projects to build their own confidential private AI products.
A growing number of confidential compute offerings are being offered by the large cloud providers that provide access to Trusted Execution Environments (TEEs). These include: AWS Nitro, Google Confidential Compute and Azure Confidential Compute. Tokenized confidential compute offerings such as Marlin Oyster and Super Protocol have also emerged recently.
These compute offerings typically allow a container (such as a Docker instance) to be deployed within a secure enclave on secure TEE hardware. The enclave has a range of verification and security measures that can prove that both the code and the data running in the enclave is the code you expect and that the enclave has been deployed in a tamper-resistant manner.
There are some important limitations to these secure enclaves, namely:
There is no direct access available to the enclave from the infrastructure operator. Communication occurs via a dedicated virtual socket between the secure enclave and the host machine (*).
There is no disk storage available, everything must be stored in RAM.
Direct GPU access is typically not available within the secure enclave (necessary for high performance LLM training and inference), however this capability is expected to be available in early 2025.
(*) In some instances the infrastructure operator controls both the hardware attestation key and the cloud infrastructure which introduces security risks that need to be carefully worked through, but is outside the scope of this document.
The Verida network is effectively a database offering high performance data synchronization and decryption. While secure enclaves do not have local disk access (by design), it is possible to give a secure enclave a private key, enabling the enclave to quickly download user data, load it into memory and perform operations.
While enclaves do not have direct access to the Internet, it is possible to facilitate secure socket connections between the host machine and enclave to “proxy” web requests to the outside world. This increases the surface area of possible attacks on the security of the enclave, but is also a necessary requirement for confidential compute that interacts with other web services.
It is critical that confidential AI inference for user prompts has a fast response time to ensure a high quality experience for end users. Direct GPU access via confidential compute is most likely necessary to meet these requirements. Access to GPUs with TEEs is currently limited, however products such as the NVIDIA H100 offer these capabilities and these capabilities will be made available for use within the Verida network in due course.
Verida offers a self-sovereign compute infrastructure stack that exists on top of confidential compute infrastructure.
The self-sovereign compute infrastructure provides the following guarantees:
User data is not accessible by infrastructure node operators.
Runtime code can be verified to ensure it is running the expected code.
Users are in complete control over their private data and can grant / revoke access to third parties at any time.
Third-party developers can build and deploy code that will operate on user data in a confidential manner.
Users are in complete control over the compute services that can operate on their data and can grant / revoke access to third parties at any time.
There are two distinct types of compute that have different infrastructure requirements; Stateless Confidential Compute and Stateful Confidential Compute.
This type of computation is stateless, it retains no user data between API requests. However, it can request user data from other APIs and process that user data in a confidential manner.
Here are some examples of Generic Stateless Compute that would operate on the network.
Private Data Bridge facilitates users connecting to third-party platform APIs (ie: Meta, Google, Amazon, etc.). These nodes must operate in a confidential manner as they store API secrets, handle end user access / refresh tokens to the third-party platforms, pull sensitive user data from those platforms, and then use private user keys to store that data in users’ private databases on the Verida network.
LLM APIs accept user prompts that contain sensitive user data, so they must operate in a confidential compute environment.
AI APIs such as AI prompt services and AI agent services provide the “glue” to interact between user data and LLMs. An AI service can use the User Data APIs (see below) to directly access user data. This enables it to facilitate retrieval-augmented generation (RAG) via the LLM APIs, leveraging user data. These APIs may also save data back to users’ databases as a result of a request (i.e., saving data into a vector database for future RAG queries).
See “Self-Sovereign AI Interaction Model” from Part 1 for a breakdown of how these generic compute services can interact together to provide AI services on user data.
This type of computation is stateful, where user data remains available (in memory) for an extended period of time. This enhances performance and, ultimately, the user experience for end users.
A User Data API will enable authorized third party applications (such as private AI agents) to easily and quickly access decrypted private user data. It is assumed there is a single User Data API, however in reality it is likely there will be multiple API services that operate on different infrastructure.
Here are some examples of the types of data that would be available for access:
Chat history across multiple platforms (Telegram, Signal, Slack, Whatsapp, etc.)
Web browser history
Corporate knowledge base (ie: Notion, Google Drive, etc)
Emails
Financial transactions
Product purchases
Health data
Each of these data types have different volumes and sizes, which will also differ between users. It’s expected the total storage required for an individual user would be somewhere between 100MB and 2GB, whereas enterprise knowledge bases will be much larger.
In the first phase, the focus will be on structured data, not images or videos. This aligns with Verida’s existing storage node infrastructure that provides and aids the development of a first iteration of data schemas for AI data interoperability.
The User Data API exposes endpoints to support the following data services:
Authentication for decentralized identities to connect their account to a User Data API Node
Authentication to obtain access and refresh tokens for third-party applications
Database queries that execute over a user’s data
Keyword (Lucene) style search over a user’s data
Vector database search over a user’s data
Third party applications obtain an access token that allows scoped access to user data, based on the consent granted by the user.
A decentralized identity on the Verida network can authorize three or more self-sovereign compute nodes on the network, to manage access to their data for third-party applications. This is via the serviceEndpoint capability on the identity’s DID Document. This operates in the same way that the current Verida database storage network allocates storage nodes to be responsible for user data.
Secure enclaves have no disk access, however user data is available (encrypted) on the Verida network and can be synchronized on demand given the appropriate user private key. It’s necessary for user data to be “hot loaded” when required which involves synchronizing the encrypted user data from the Verida network, decrypting it, storing it in memory and then adding other metadata (i.e., search indexes). This occurs when an initial API request is made, ensuring user data is ready for fast access for third-party applications.
After a set period of time of inactivity (i.e., 1 hour) the user data will be unloaded from memory to save resources on the underlying compute node. In this way, a single User Data API node can service requests for multiple decentralized identities at once.
It will be necessary to ensure “hot loading” is fast enough to minimize the first interaction time for end users. It’s also essential these compute nodes have sufficient memory to load data for multiple users at once. Verida has developed an internal proof-of-concept to verify the “hot loading” concept with user data will be a viable solution.
For enhanced privacy and security, the data and execution for each decentralized identity will operate in an isolated VM within the secure enclave of the confidential compute node.
Confidential Compute Nodes running on the Verida Self-Sovereign Compute Network operate a web server within a secure enclave environment to handle compute requests and responses.
There will be different types of nodes (i.e., LLM, User API) that will have different code running on them depending on the service(s) they are providing.
For maximum flexibility, advanced users and developers will be able to run compute nodes locally, on any type of hardware.
Nodes have key requirements they must adhere to:
GPU access is required for some compute nodes (i.e., LLM nodes), but not others. As such, the hardware requirements for each node will depend on the type of compute services running on the node.
Code Verifiability is critical to ensure trust in the compute and security of user data. Nodes must be able to attest the code they are running has not been tampered with.
Upgradability is essential to keep nodes current with the latest software versions, security fixes and other patches. Coordination is required to ensure applications can ensure their code is running on the latest node versions.
API endpoints are the entry point for communicating with nodes. It’s essential a web server host operates within the secure enclave to communicate with the outside world.
SSL termination must occur within the secure enclave to ensure the host machine can’t access API requests and responses.
Resource restraints will exist on each node (i.e., CPU, memory) that will limit the number of active requests they can handle. The network and nodes will need to coordinate this to ensure nodes are selected that have sufficient resources available to meet any given request.
In order to create an efficient and highly interoperable ecosystem of self-sovereign API’s, it’s necessary to have a set of common data standards. Verida’s self-sovereign database storage network provides this necessary infrastructure via guaranteed data schemas within encrypted datasets, providing a solid foundation for data interoperability.
Developers can build new self-sovereign compute services that can be deployed on the network and then used by other services. This provides an extensible ecosystem of API’s that can all communicate with each other to deliver highly complex solutions for end users.
Over time, we expect a marketplace of private AI products, services and APIs to evolve.
Verida’s self-sovereign compute network will enable infrastructure operators to deploy and register a node of a particular service type. When an API needs to send a request to one of those service types, it can perform a “service lookup” on the Verida network to identify a suitable trusted, verifiable node it can use to send requests of the required service type.
It is essential to protect user privacy within the ecosystem and prevent user data leaking to non-confidential compute services outside the network. Each service deployed to the network will be running verifiable code, running on verifiable confidential compute infrastructure.
In addition, each service will only communicate with other self-sovereign compute services. Each API request to another self-sovereign compute service will be signed and verified to have been transmitted by another node within the self-sovereign network.
The VDA token will be used for payment to access self-sovereign compute services. A more detailed economic model will be provided, however the following key principles are expected to apply.
End users will pay on a “per-request” basis to send confidential queries to compute nodes and the services they operate. The cost per request will be calculated in a standardized fashion that balances the computation power of a node, memory usage and request time. Applications can sponsor the request fees on behalf of the user and then charge a subscription fee to cover the cost, plus profit, much like a traditional SaaS model.
Node operators will be compensated for providing the confidential compute infrastructure to Verida’s Self-Sovereign Compute Network.
Builders of services (i.e., AI Prompts and Agents) will be able to set an additional fee for using their compute services, above and beyond the underlying “per-request” compute cost. This open marketplace for AI Agents and other tools drives innovation and provides a seamless way for developers to generate revenue from the use of their intellectual property.
Verida Network will charge a small protocol fee (similar to a blockchain gas fee) on compute fees.
Verida’s Private Data Bridge allows users to reclaim their private data from platforms such as Meta, Google, X, email, LinkedIn, Strava, and much more.
Users on the Verida network could push their personal data into a confidential compute service that anonymizes their data (or generates synthetic data) which is made available to various AI data marketplaces. This provides an option for users to monetize their data, without risk of data leakage, while unlocking highly valuable and unique datasets such as private messages, financial records, emails, healthcare data for training purposes.
There is a vast array of managed wallet services available today that offer different trade-offs between user experience and security.
Having an always available cloud service that can protect user’s private keys, but still provide multiple authorization methods for a user is extremely useful to onboard new users and provide additional backup protection measures for existing users.
Such a managed wallet service becomes rather trivial to build and deploy on the Verida self-sovereign compute network.
Verida has extensive experience working with decentralized identity and verifiable credential technology, in combination with many ecosystem partners.
There is a significant pain point in the industry, whereby developers within credential ecosystems are required to integrate many disparate developer SDK’s to offer an end-to-end solution. This is due to the self-sovereign nature of credentials and identity solutions where a private key must be retained on end user devices to facilitate end-to-end security.
Verida’s self-sovereign compute network can provide a viable alternative, whereby application developers can replace complex SDK integrations with simple self-sovereign APIs. This makes integration into mobile applications (such as identity wallets) and traditional web applications much easier, simpler and viable.
This could be used to provide simple API integrations to enable:
Identity wallets to obtain access to a user’s verifiable credentials
End users to pre-commit selective disclosure rules for third party applications or identity wallets, without disclosing their actual credentials
Provide trusted, verifiable universal resolvers
Trust registry APIs
Any complex SDK that requires a user’s private key to operate, could be deployed as a micro service on Verida’s self-sovereign compute network to provide a simpler integration and better user experience.
Verida’s mission to empower individuals with control over their data continues to drive our innovations as we advance our infrastructure. This Litepaper outlines how the Verida Network is evolving from decentralized, privacy-preserving databases to include decentralized, privacy-preserving compute capabilities, addressing critical issues in AI data management and introducing valuable new use cases for user-controlled data.
As AI faces mounting challenges with data quality, privacy, and transparency, Verida is at the forefront of addressing these issues. By expanding our network to support privacy-preserving compute, we enable the more effective safeguarding of private data while allowing it to be securely shared with with leading AI models. This approach ensures end-to-end privacy and opens the door to hyper-personalized and secure AI experiences.
Our solution addresses three fundamental problems: enabling user access to their private data, providing secure storage and sharing, and ensuring confidential computation. Verida’s “Private Data Bridge” allows users to securely reclaim and manage their data from various platforms and facilite its use in personalized AI applications without compromising privacy.
While we are not focusing on decentralized AI model training or distributed inference, Verida is committed to offering high-performance, secure, and trusted infrastructure for managing private data. We are collaborating with partners developing private AI agents, AI data marketplaces, and other privacy-centric AI solutions, paving the way for a more secure and private future in AI. This empowers users to be confident about the ways their data is used, and receive compensation when they do choose to share elements of their personal data.
As we continue to build on these advancements, Verida remains dedicated to transforming how private data is utilized and protected in the evolving landscape of AI.
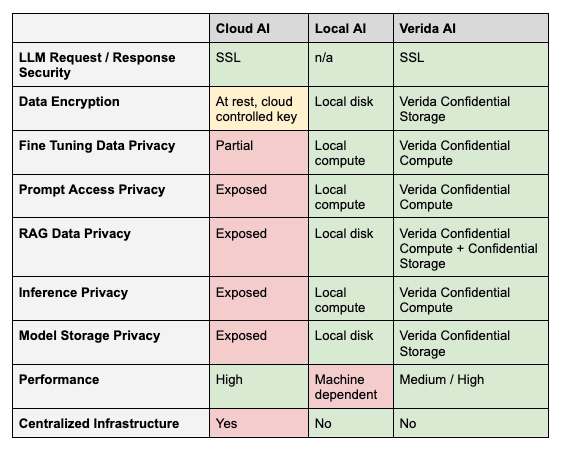
Verida is providing key infrastructure that will underpin the next generation of the privacy preserving AI technology stack. The Verida Network provides private storage, sources of personal data and expandable infrastructure to make this future a reality.
Let’s dive into each of these areas in more detail.
The Verida network is designed for storing private, personal data. It is a for storing structured database data for any type of application.
Data stored on the network is protected with a user’s private key, ensuring they are the only account that can request access to, and encrypt their data (unless they provide permission to another account).
This makes the Verida Network ideal for storing private AI models for end users. The network’s high performance (leveraging P2P web socket connections), makes it suitable for high speed read / write applications such as training LLMs.
We’ve all heard the saying “garbage in, garbage out” when it comes to data. This also applies to training AI models. They are only as good as the data they are fed for training purposes.
The Verida ecosystem provides a broad range of capabilities that make it ideally suited to being a primary source of highly valuable data for training AI models.
Verida has been developing an API data connector framework that enables users to easily connect to existing API’s of centralized platforms and claim their personal data, that they can securely store on the Verida network.
Users on the Verida network will be able to pull health activity data from the likes of Strava and Fitbit. They can pull their private messages from chat platforms, their data from Google and Apple accounts. This can all then be leveraged to train AI models for exclusive use by the user, or that data can be anonymized and contributed to larger training models.
Establishing a data-driven token economy offers a promising avenue for fostering fairness among all stakeholders. Eventually, major tech and data corporations may introduce a token system for service payments, thereby incentivizing users to share their data.
For an example; individuals could leverage their anonymous health data to train AI models for healthcare research and receive token rewards in return. These rewards could then be utilized for subscribing to the service or unlocking premium features, establishing a self-sustaining cycle where data sharing leads to increased service access as a reward. This model fosters a secure and equitable relationship between data contribution and enhanced service access, ensuring that those who contribute more to the ecosystem reap greater benefits in return.
Users could also use their personal data to train AI models designed just for them. Imagine a digital AI assistant guiding you through your life. Suggesting meetup events to attend to improve your career, suggesting a cheaper greener electricity retailer based on your usage, suggesting a better phone plan or simply reminding you of an event you forgot to add to your calendar.
As touched on in “”, privacy preserving AI will need access to privacy preserving computation to train AI models and respond to user prompts.
Verida is not in the business of providing private decentralized computation, however the Verida identity framework (based on the DID-Core W3C standard) is expandable to connect to this type of Decentralized Physical Infrastructure (DePIN).
Identities on the Verida network can currently be linked to three types of DePIN; Database storage, Private inbox messages, Private notifications. This architecture can easily be extended to support new use cases such as “Private compute” or “Personal AI prompt API”.
With the appropriate partners who support decentralized private compute, there is a very clear pathway to enable personalized, privacy preserving AI leveraging a 100% DePIN technology stack.
This is incredibly exciting, as it will provide a more secure, privacy preserving solution as an alternative to giving all our data to large centralized technology companies.