Learn
Dive deeper into the technology, architecture and design decisions that power Verida AI
Anatomy of an AI Agent
Artificial Intelligence (AI) is rapidly evolving beyond simple prompts and chat interactions. While tools like ChatGPT and Meta AI have made conversations with large language models (LLMs) commonplace, the future of AI lies in agents—sophisticated digital entities capable of knowing everything about us and acting on our behalf. Let’s dive into what makes up an AI agent and why privacy is a crucial component in their development.
Dynamic loading of personal data for realtime AI
How fast can data, stored in a decentralized database storage network like Verida, be made available to a personal AI agent? This is a critical question as huge time lags will create a poor user experience, making any personal AI products unviable.
Data Privacy Issues and how Verida is enabling the privacy preserving AI tech stack
The Verida Network provides storage infrastructure perfect for AI solutions and the upcoming data connector framework will create a new data economy that benefits end users.
Verida Technical Litepaper: Self-Sovereign Confidential Compute Network to Secure Private AI
This Technical Litepaper presents a high-level outline of how the Verida Network is growing beyond decentralized, privacy preserving databases, to support decentralized, privacy-preserving compute optimized for handling private data.
Anatomy of an AI Agent
A breakdown of the key components that will make up our future AI Agents
Artificial Intelligence (AI) is rapidly evolving beyond simple prompts and chat interactions. While tools like ChatGPT and Meta AI have made conversations with large language models (LLMs) commonplace, the future of AI lies in agents—sophisticated digital entities capable of knowing everything about us and acting on our behalf. Let’s dive into what makes up an AI agent and why privacy is a crucial component in their development.
1. The Brain: The Core of AI Computation
Every AI agent needs a "brain"—a system that processes and performs tasks for us. This brain is an amalgamation of various technologies:
Large Language Models (LLMs): The foundation of most AI agents, these models are trained to understand and generate human-like responses.
Fine-Tuning: A step further, where LLMs are tailored using personal data to offer more personalized and accurate outputs.
Retrieval-Augmented Generation (RAG): A method that smartly incorporates user data into the context window, helping the LLM access relevant personal information and provide more meaningful interactions.
Databases: Both vector and traditional databases come into play, enabling the AI agent to store and retrieve vast amounts of information efficiently.
The synergy of these technologies forms an AI's cognitive abilities, allowing it to generate intelligent and context-aware responses.
2. The Heart: Data Integration and Personalization
An AI agent's brain is only as good as the data it has access to. The "heart" of the AI agent is its data engine, which powers personalization. This engine requires access to various types of user data, such as:
Emails and Private Messages: Insights into communication preferences.
Health Records and Activity Data: Information from fitness trackers or health apps like Apple Watch.
Financial Records: Transaction histories and financial trends.
Shopping and Transaction History: Preferences and past purchases for tailored shopping experiences.
The more data an AI agent has, the better it can serve as a "digital twin," representing and anticipating user needs.
3. The Limbs: Acting on Your Behalf
For an AI agent to be genuinely useful, it must do more than just think and understand—it needs the capability to act. This means connecting to various services and APIs to:
Book Flights or Holidays: Manage travel arrangements autonomously.
Order Services: Call for a ride, order groceries, or make appointments.
Send Communications: Draft and send emails or messages on your behalf.
To enable these capabilities, the agent must be seamlessly integrated with a wide array of digital services and platforms, with user consent being a critical aspect.
4. Privacy and Security: The Final Piece
As these agents become more capable and integrate deeply into our lives, ensuring privacy and security is paramount. The more data an agent holds, the more vulnerable it becomes to potential misuse. Here's why this matters:
Self-Sovereign Technologies: The ideal future of AI agent technology is built on decentralized and self-sovereign systems. These systems empower users as the sole owners of their data and AI computation.
Guarding Against Big Tech Control: Companies like Google, Apple, and Microsoft already possess vast amounts of user data. Concentrating even more data into their control can lead to potential exploitation. A decentralized model prevents these corporations from having unrestricted access to personal AI agents, ensuring that only the user can access their private information.
Final Thoughts
For AI agents to flourish and be trusted, they must be built on a foundation that respects user privacy and autonomy. In essence, a robust AI agent will consist of:
A Brain: Advanced AI computation.
A Heart: A rich data engine powered by user data.
Limbs: The ability to take action on behalf of the user.
However, without strong privacy and security measures, these agents could pose significant risks. The future of AI agents hinges on creating a technology layer that preserves individual ownership, enforces privacy, and limits the control of major tech companies. By ensuring that only the agent’s owner can access its data, we set the stage for a safer, more empowering digital future.
Dynamic Loading of Data for Realtime AI
A breakdown on how to make personal data available for AI use cases
At Verida, We are working rapidly towards enabling personal data to be connected to AI for training and inference, in an end-to-end privacy preserving manner.
One of the questions to answer is how fast can data, stored in a decentralized database storage network like Verida, be made available to a personal AI agent. This is a critical question as huge time lags will create a poor user experience, making any personal AI products unviable.
There are many ways to use AI to communicate with data, however in this case we are assuming a Retrieval-Augmented Generation (RAG) approach.
Dynamic User Data Queries
The current architecture we are researching involves a “User Data API” that unlocks personal data stored (encrypted) on the Verida network, decrypts the data and then makes it available to AI agents and large language models (LLM’s) on demand.
This poses key latency questions:
What is the latency to fetch encrypted data from the network?
What is the latency to decrypt the data and make it queryable?
What is the latency to make the data searchable via Lucene style search queries?
While (3) isn’t absolutely necessary, at this stage it seems reasonable to assume a Lucene style search is a powerful tool to allow fast, flexible search queries across user data.
Test Setup
I used an early version of the Verida Personal Data Bridge (source code) to pull my most recent 4,000 emails. This resulted in 250MB of raw database data (including PDF attachments converted to text), which became 330MB once database indexes were included.
I then ran the Verida User Data API to hit the search endpoint that searches all my data matching the email schema (https://common.schemas.verida.io/social/email/v0.1.0/schema.json): http://localhost:5022/search/ds/aHR0cHM6Ly9jb21tb24uc2NoZW1hcy52ZXJpZGEuaW8vc29jaWFsL2VtYWlsL3YwLjEuMC9zY2hlbWEuanNvbg===?q=name:Luca
For testing purposes, the Personal Data Bridge and User Data API are running locally on my Macbook Pro. The Verida account is on the Banksia testnet, connected to a Storage Node running on my local machine.
Test Results
Here’s the timed output from this initial set of tests:
Latency
Making a /search request involves the following time sensitive operations:
Time to sync encrypted user data from the Verida network to the local machine
Time to decrypt the user data into a decrypted database
Time to load all records from the decrypted database into memory
Time to load all data into an in memory Lucene index and query it
The screenshot shows three requests running over 4,000 of my personal emails.
Request 1
The first request took 3m 41s to complete steps 1,2,3.
Step 4 took an incredibly fast 38 ms.
Request 2
The second request used a cached copy of the Lucene index so only needed to complete step 4, again returning results in 38 ms.
Request 3
For the third request, I shut down the server, which cleared the in memory Lucene cache.
This request didn’t need to complete step 1. It completed steps 2 and 3 in 34s and generated the Lucene results in 26ms.
Note: Step 1 is actually pulling data from a Storage Node running on my local machine, not the network itself. As such step 1 is a bit faster than real world usage which would have this code running in data centres with fast pipes.
Memory
The baseline memory usage of the User Data API server is (bytes):
{
"rss": 115982336,
"heapTotal": 36827136,
"heapUsed": 33001104,
"external": 2117266,
"arrayBuffers": 54788
}After loading the data in-memory (bytes):
{
"rss": 772591616,
"heapTotal": 362926080,
"heapUsed": 351119608,
"external": 2156712,
"arrayBuffers": 82355
}This shows an increase in memory usage for the process from a baseline of 115MB to 772MB.
Discussion
Here’s a breakdown of the learnings and a discussion on each.
It’s important to note that this infrastructure is intended to be run within secure enclaves to guarantee end-to-end privacy of user data. As it currently stands, secure enclaves only support in-memory storage, with no access to long term physical disk storage.
Latency
These are roughly extrapolated times for each step:
Step 1: Sync encrypted data: ~3 minutes
Step 2 & 3: Locally decrypt data and load into memory: ~34 seconds
Step 4: Load data into Lucene and run query: 34 milliseconds
The time to query the data is incredibly fast at 34ms, which is a huge positive.
However, the time to load the data in Step 1 is a blocker to a great user experience. That being said, this step only needs to occur once for any given server.
Under the Verida model of using decentralized identifiers, each Verida account will specify specific confidential compute nodes to act on their behalf. These nodes can sync this data once and then receive regular updates (using the Verida network real-time sync capabilities), keeping it up-to-date at all times.
The 34 seconds to decrypt and load into memory only needs to happen when the User Data API doesn’t have user data in it’s memory cache. This will happen when; 1) The server starts for the first time, or 2) If the cache is cleared (likely to happen after a period of inactivity for a user).
In reality, there may be a 30 second delay for this load process when a user makes their first request and then all subsequent requests should be very fast. Better hardware will drastically improve this load time.
Memory Usage
Memory usage ballooned from 115MB to 772MB, an increase of 657MB. The raw uncompressed data (stored in memory database) was 330MB including indexes. 657MB is almost exactly 2x330MB which makes sense, because the data is actually loaded into memory twice. One copy is an in-memory database, the second copy is an in-memory Lucene database.
It’s quite possible the Lucene search service proves to be more useful than the in-memory database, allowing it to be dropped and halving that memory usage.
A future piece of work is to investigate running Lucene locally within the secure enclave, instead of storing in-memory. This would potentially eliminate the 30 second load time and significantly reduce the memory usage of the User Data API server.
4,000 emails?
Our vision is to enable AI to access all your digital data; email history, message history from chat platforms, search and browser history, health care data, financial records and more. That obviously requires a lot more than the 330MB of data used in this example.
The Personal Data Bridge supports pulling Facebook page likes and posts. I have pulled down over 3,000 facebook posts (excluding images and videos) which was less than 10MB.
We are still learning the volume of data for each dataset as we connect more sources to the Personal Data Bridge, but it’s probably safe to assume that email will be the largest data set for most people.
In my case 4,000 emails represented just 2 months of one of my multiple inboxes. The vast majority of those messages are junk / spam that I never intend to read. It may be sensible to add an additional processing layer over the data to eliminate emails that aren’t worth indexing. This will save memory and reduce time.
Extending that idea further, there will likely be a need to build additional metadata based on your personal data to help AI assistants to quickly know more about you. For example, you can enable a LLM to search your email and social media history to create a profile for you; age, gender, family, income, food preferences and much more. This is incredibly useful context to help guide any personal AI assistant, when combined with conducting real time search queries for specific prompts.
Where next?
The current focus is getting an end-to-end solution that can be run on a local machine to connect your personal data to AI LLM’s.
While there are some performance bottlenecks mentioned above that could be investigated further, there is nothing that is an obvious blocker.
To that end, the next key priority is to be able to write a prompt (ie: Create a haiku of the conversation I had with my Mum about Mars) and have it sent to a locally running LLM (ie: Llama3) that has access to user data via the Lucene index to produce a meaningful result.
Data Privacy Issues
Top Three Data Privacy Issues Facing AI Today. AI has taken the world by storm, but there are some critical privacy issues that need to be considered.
AI (artificial intelligence) has caused frenzied excitement among consumers and businesses alike – driven by a passionate belief that LLMs (large language models) and tools like ChatGPT will transform the way we study, work and live.
But just like in the internet’s early days, users are jumping in without considering how their personal data is used – and the impact this could have on their privacy.
There have already been countless examples of data breaches within the AI space. In March 2023, OpenAI temporarily took ChatGPT offline after a ‘significant’ error meant users were able to see the conversation histories of strangers.
That same bug meant the payment information of subscribers – including names, email addresses and partial credit card numbers – were also in the public domain.
In September 2023, a staggering 38 terabytes of Microsoft data was inadvertently leaked by an employee, with cybersecurity experts warning this could have allowed attackers to infiltrate AI models with malicious code.
Researchers have also been able to manipulate AI systems into disclosing confidential records.
In just a few hours, a group called Robust Intelligence was able to solicit personally identifiable information from Nvidia software and bypass safeguards designed to prevent the system from discussing certain topics.
Lessons were learned in all of these scenarios, but each breach powerfully illustrates the challenges that need to be overcome for AI to become a reliable and trusted force in our lives.
Gemini, Google’s chatbot, even admits that all conversations are processed by human reviewers – underlining the lack of transparency in its system.
“Don’t enter anything that you wouldn’t want to be reviewed or used,” says an alert to users warns.
AI is rapidly moving beyond a tool that students use for their homework or tourists rely on for recommendations during a trip to Rome.
It’s increasingly being depended on for sensitive discussions – and fed everything from medical questions to our work schedules.
Because of this, it’s important to take a step back and reflect on the top three data privacy issues facing AI today, and why they matter to all of us.
1. Prompts aren’t private
Tools like ChatGPT memorize past conversations in order to refer back to them later. While this can improve the user experience and help train LLMs, it comes with risk.
If a system is successfully hacked, there’s a real danger of prompts being exposed in a public forum.
Potentially embarrassing details from a user’s history could be leaked, as well as commercially sensitive information when AI is being deployed for work purposes.
As we’ve seen from Google, all submissions can also end up being scrutinized by its development team.
Samsung took action on this in May 2023 when it banned employees from using generative AI tools altogether. That came after an employee uploaded confidential source code to ChatGPT.
The tech giant was concerned that this information would be difficult to retrieve and delete, meaning IP (intellectual property) could end up being distributed to the public at large.
Apple, Verizon and JPMorgan have taken similar action, with reports suggesting Amazon launched a crackdown after responses from ChatGPT bore similarities to its own internal data.
As you can see, the concerns extend beyond what would happen if there’s a data breach but to the prospect that information entered into AI systems could be repurposed and distributed to a wider audience.
Companies like OpenAI are already facing multiple lawsuits amid allegations that their chatbots were trained using copyrighted material.
2. Custom AI models trained by organizations aren’t private
This brings us neatly to our next point – while individuals and corporations can establish their custom LLM models based on their own data sources, they won’t be fully private if they exist within the confines of a platform like ChatGPT.
There’s ultimately no way of knowing whether inputs are being used to train these massive systems – or whether personal information could end up being used in future models.
Like a jigsaw, data points from multiple sources can be brought together to form a comprehensive and worryingly detailed insight into someone’s identity and background.
Major platforms may also fail to offer detailed explanations of how this data is stored and processed, with an inability to opt out of features that a user is uncomfortable with.
Beyond responding to a user’s prompts, AI systems increasingly have the ability to read between the lines and deduce everything from a person’s location to their personality.
In the event of a data breach, dire consequences are possible. Incredibly sophisticated phishing attacks could be orchestrated – and users targeted with information they had confidentially fed into an AI system.
Other potential scenarios include this data being used to assume someone’s identity, whether that’s through applications to open bank accounts or deepfake videos.
Consumers need to remain vigilant even if they don’t use AI themselves. AI is increasingly being used to power surveillance systems and enhance facial recognition technology in public places.
If such infrastructure isn’t established in a truly private environment, the civil liberties and privacy of countless citizens could be infringed without their knowledge.
3. Private data is used to train AI systems
There are concerns that major AI systems have gleaned their intelligence by poring over countless web pages.
Estimates suggest 300 billion words were used to train ChatGPT – that’s 570 gigabytes of data – with books and Wikipedia entries among the datasets.
Algorithms have also been known to depend on social media pages and online comments.
With some of these sources, you could argue that the owners of this information would have had a reasonable expectation of privacy.
But here’s the thing – many of the tools and apps we interact with every day are already heavily influenced by AI – and react to our behaviors.
The Face ID on your iPhone uses AI to track subtle changes in your appearance.
TikTok and Facebook’s AI-powered algorithms make content recommendations based on the clips and posts you’ve viewed in the past.
Voice assistants like Alexa and Siri depend heavily on machine learning, too.
A dizzying constellation of AI startups is out there, and each has a specific purpose. However, some are more transparent than others about how user data is gathered, stored and applied.
This is especially important as AI makes an impact in the field of healthcare – from medical imaging and diagnoses to record-keeping and pharmaceuticals.
Lessons need to be learned from the internet businesses caught up in privacy scandals over recent years.
Flo, a women’s health app, was accused by regulators of sharing intimate details about its users to the likes of Facebook and Google in the 2010s.
Where do we go from here?
AI is going to have an indelible impact on all of our lives in the years to come. LLMs are getting better with every passing day, and new use cases continue to emerge.
However, there’s a real risk that regulators will struggle to keep up as the industry moves at breakneck speed.
And that means consumers need to start securing their own data and monitoring how it is used.
Decentralization can play a vital role here and prevent large volumes of data from falling into the hands of major platforms.
DePINs (decentralized physical infrastructure networks) have the potential to ensure everyday users experience the full benefits of AI without their privacy being compromised.
Not only can encrypted prompts deliver far more personalized outcomes, but privacy-preserving LLMs would ensure users have full control of their data at all times – and protection against it being misused.
Web3 & DePIN solves AI's privacy problems
The emergence of Decentralized Physical Infrastructure Networks (DePIN) are a linchpin for providing privacy preserving decentralized infrastructure to power the next generation of large language mode
Artificial intelligence (AI) has become an undeniable force in shaping our world. From personalized recommendations to medical diagnosis, AI's impact is undeniable. However, alongside its potential lies a looming concern: data privacy. Traditional AI models typically rely on centralized data storage and centralized computation, raising concerns about ownership, control, and potential misuse.
See part 1 of this series, “Top3 data privacy issues facing AI today”, for a breakdown of key privacy issues which we will explain how web3 can help alleviate these problems.
The emergence of Decentralized Physical Infrastructure Networks (DePIN) are a linchpin for providing privacy preserving decentralized infrastructure to power the next generation of large language models (LLMs).
At a high level, DePINs can provide access to decentralized computation and storage resources that are beyond the control of any single organization. If this computation and storage can be built in such a way that it is privacy preserving; ie: those operating the infrastructure have no access to underlying data or computation occurring, this is an incredibly robust foundation for privacy preserving AI.
Let’s dive deeper into how that would look, when addressing the top three data privacy issues.
Privacy of user prompts
Safeguarding privacy of user prompts has become an increasingly critical concern in the world of AI.
An end user can initiate a connection with a LLM hosted within a decentralized privacy-prserving compute engine called a Trusted Execution Environment (TEE), which provides a public encryption key. The end user encrypts their AI prompts using that public key and sends the encrypted prompts to the secure LLM.
Within this privacy-preserving environment, the encrypted prompts undergo decryption using a key only known by the TEE. This specialized infrastructure is designed to uphold the confidentiality and integrity of user data throughout the computation process.
Subsequently, the decrypted prompts are fed into the LLM for processing. The LLM generates responses based on the decrypted prompts without ever revealing the original, unencrypted input to any party beyond the authorized entities. This ensures that sensitive information remains confidential and inaccessible to any unauthorized parties, including the infrastructure owner.
By employing such privacy-preserving measures, users can engage with AI systems confidently, knowing that their data remains protected and their privacy upheld throughout the interaction. This approach not only enhances trust between users and AI systems but also aligns with evolving regulatory frameworks aimed at safeguarding personal data.
Privacy of custom trained AI models
In a similar fashion, decentralized technology can be used to protect the privacy of custom-trained AI models that are leveraging proprietary data and sensitive information.
This starts with preparing and curating the training dataset in a manner that mitigates the risk of exposing sensitive information. Techniques such as data anonymization, differential privacy, and federated learning can be employed to anonymize or decentralize the data, thereby minimizing the potential for privacy breaches.
Next, an end user with a custom-trained Language Model (LLM) safeguards its privacy by encrypting the model before uploading it to a decentralized Trusted Execution Environment.
Once the encrypted custom-trained LLM is uploaded to the privacy-preserving compute engine, the infrastructure decrypts it using keys known only to TEE. This decryption process occurs within the secure confines of the compute engine, ensuring that the confidentiality of the model remains intact.
Throughout the training process, the privacy-preserving compute engine facilitates secure communication between the end user's infrastructure and any external parties involved in the training process, ensuring that sensitive data remains encrypted and confidential at all times. In a decentralized world, this data sharing infrastructure and communication will likely exist on a highly secure and fast protocol such as the Verida Network.
By adopting a privacy-preserving approach to model training, organizations can mitigate the risk of data breaches and unauthorized access while fostering trust among users and stakeholders. This commitment to privacy not only aligns with regulatory requirements but also reflects a dedication to ethical AI practices in an increasingly data-centric landscape.
Private data to train AI
AI models are only as good as the data they have access to. The vast majority of data is generated on behalf of, or by, individuals. This data is immensely valuable for training AI models, but must be protected at all costs due to its sensitivity.
End users can safeguard their private information by encrypting it into private training datasets before submission to a LLM training program. This process ensures that the underlying data remains confidential throughout the training phase.
Operating within a privacy-preserving compute engine, the LLM training program decrypts the encrypted training data for model training purposes while upholding the integrity and confidentiality of the original data. This approach mirrors the principles applied in safeguarding user prompts, wherein the privacy-preserving computation facilitates secure decryption and utilization of the data without exposing its contents to unauthorized parties.
By leveraging encrypted training data, organizations and individuals can harness the power of AI model training while mitigating the risks associated with data exposure. This approach enables the development of AI models tailored to specific use cases, such as utilizing personal health data to train LLMs for healthcare research applications or crafting hyper-personalized LLMs for individual use cases, such as digital AI assistants.
Following the completion of training, the resulting LLM holds valuable insights and capabilities derived from the encrypted training data, yet the original data remains confidential and undisclosed. This ensures that sensitive information remains protected, even as the AI model becomes operational and begins to deliver value.
To further bolster privacy and control over the trained LLM, organizations and individuals can leverage platforms like the Verida Network. Here, the trained model can be securely stored, initially under the private control of the end user who created it. Utilizing Verida's permission tools, users retain the ability to manage access to the LLM, granting permissions to other users as desired. Additionally, users may choose to monetize access to their trained models by charging others with crypto tokens for accessing and utilizing the model's capabilities.
Privacy Preserving AI Tech Stack
Verida is providing key infrastructure that will underpin the next generation of the privacy preserving AI technology stack. The Verida Network provides private storage, sources of personal data and expandable infrastructure to make this future a reality.
Let’s dive into each of these areas in more detail.
Private storage for personal AI models
The Verida network is designed for storing private, personal data. It is a highly performant, low cost, regulatory compliant solution for storing structured database data for any type of application.
Data stored on the network is protected with a user’s private key, ensuring they are the only account that can request access to, and encrypt their data (unless they provide permission to another account).
This makes the Verida Network ideal for storing private AI models for end users. The network’s high performance (leveraging P2P web socket connections), makes it suitable for high speed read / write applications such as training LLMs.
Source of data for training AI models
We’ve all heard the saying “garbage in, garbage out” when it comes to data. This also applies to training AI models. They are only as good as the data they are fed for training purposes.
The Verida ecosystem provides a broad range of capabilities that make it ideally suited to being a primary source of highly valuable data for training AI models.
Verida has been developing an API data connector framework that enables users to easily connect to existing API’s of centralized platforms and claim their personal data, that they can securely store on the Verida network.
Users on the Verida network will be able to pull health activity data from the likes of Strava and Fitbit. They can pull their private messages from chat platforms, their data from Google and Apple accounts. This can all then be leveraged to train AI models for exclusive use by the user, or that data can be anonymized and contributed to larger training models.
Establishing a data-driven token economy offers a promising avenue for fostering fairness among all stakeholders. Eventually, major tech and data corporations may introduce a token system for service payments, thereby incentivizing users to share their data.
For an example; individuals could leverage their anonymous health data to train AI models for healthcare research and receive token rewards in return. These rewards could then be utilized for subscribing to the service or unlocking premium features, establishing a self-sustaining cycle where data sharing leads to increased service access as a reward. This model fosters a secure and equitable relationship between data contribution and enhanced service access, ensuring that those who contribute more to the ecosystem reap greater benefits in return.
Users could also use their personal data to train AI models designed just for them. Imagine a digital AI assistant guiding you through your life. Suggesting meetup events to attend to improve your career, suggesting a cheaper greener electricity retailer based on your usage, suggesting a better phone plan or simply reminding you of an event you forgot to add to your calendar.
Expandable infrastructure
As touched on in “How web3 and DePIN solves AI’s data privacy problems”, privacy preserving AI will need access to privacy preserving computation to train AI models and respond to user prompts.
Verida is not in the business of providing private decentralized computation, however the Verida identity framework (based on the DID-Core W3C standard) is expandable to connect to this type of Decentralized Physical Infrastructure (DePIN).
Identities on the Verida network can currently be linked to three types of DePIN; Database storage, Private inbox messages, Private notifications. This architecture can easily be extended to support new use cases such as “Private compute” or “Personal AI prompt API”.
With the appropriate partners who support decentralized private compute, there is a very clear pathway to enable personalized, privacy preserving AI leveraging a 100% DePIN technology stack.
This is incredibly exciting, as it will provide a more secure, privacy preserving solution as an alternative to giving all our data to large centralized technology companies.
Confidential Compute Litepaper
Verida Technical Litepaper: Self-Sovereign Confidential Compute Network to Secure Private AI
Introduction
Verida’s mission has always been clear: empower individuals to own and control their data. Now, we’re taking it further.
This Technical Litepaper presents a high-level outline of how the Verida Network is growing beyond decentralized, privacy preserving databases, to support decentralized, privacy-preserving compute optimized for handling private data. There are numerous privacy issues currently facing AI that web3 and decentralized physical infrastructure networks can help solve. From Verida’s perspective, this represents an expansion of our mission from allowing individuals to control their data to introducing new and powerful ways for users to benefit from their data.
Current AI Data Challenges
We are running out of high-quality data to train LLMs
Public internet data has been scraped and indexed by AI models, with researchers estimating that by 2026, we will exhaust high-quality text data for training LLMs. Next, we need to access private data, but it’s hard and expensive to access.
Private enterprise and personal AI agents need to access private data
There is a lot of excitement around the next phase of AI beyond chat prompts. Digital twins or personal AI agents that know everything about us and support every aspect of our professional and personal lives. However, to make this a reality AI models need access to private, real time context-level user data to deliver more powerful insights and a truly personalized experience.
Existing AI platforms are not private
The mainstream infrastructure providers powering the current generation of AI products have full access to prompts and training data, putting sensitive information at risk.
AI trust and transparency is a challenge
Regulation is coming to AI and it will become essential that AI models can prove the training data was high quality, ethically sourced. This is critical to reduce bias, misuse and improve safety in AI.
Data creators aren’t being rewarded
User-owned data is a critical and valuable resource for AI and those who create the data should benefit from its use. Reddit recently sold user data for $200M, while other organizations have reached similar agreements. Meta is training its AI models on user data from some countries, but excluding European users due to GDPR preventing them from doing so without user consent.
Verida’s Privacy Preserving Infrastructure
Verida has already developed the leading private decentralized database storage infrastructure (see Verida Whitepaper) which provides a solid foundation to address the current AI data challenges.
Expanding the Verida network to support privacy-preserving compute enables private, encrypted data to be integrated with leading AI models, ensuring end-to-end privacy, safeguarding data from model owners. This will unlock a new era of hyper-personal and safe AI experiences.
AI services such as ChatGPT have full access to any information users supply and have already been known to leak sensitive data. By enabling model owners access to private data, there is increased risks of data breaches, imperiling privacy, and ultimately limiting AI use cases.
There are three key problems Verida is solving to support secure private AI:
Data Access: Enabling users to extract and store their private data from third party platforms for use with emerging AI prompts and agents.
Private Storage and Sharing: Providing secure infrastructure allowing user data to be discoverable, searchable and accessible with user-consent to third party AI platforms operating within verifiable confidential compute environments.
Private Compute: Provide a verifiable, confidential compute infrastructure enabling agentic AI computation to securely occur on sensitive user data.
Supporting the above tasks, Verida is building a “Private Data Bridge”, allowing users to reclaim their data and use it within a new cohort of personalized AI applications. Users can pull their private data from platforms such as Google, Slack, Notion, email providers, LinkedIn, Amazon, Strava, and much more. This data is encrypted and stored in a user-controlled private data Vault on the Verida network.
It’s important to note that Verida is not building infrastructure for decentralized AI model training, or distributed AI inference. Rather, Verida’s focus is on providing a high performance, secure, trusted and verifiable infrastructure suitable for managing private data appropriate for AI use cases.
We have relationships with third parties that are building; private AI agents, AI data marketplaces and other privacy-centric AI use cases.
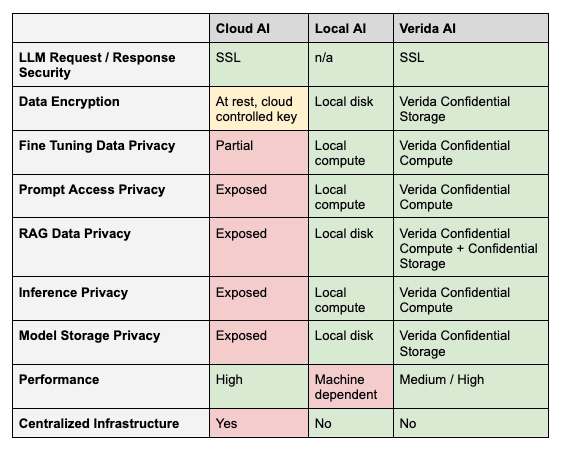
Comparing Current AI Solutions
AI solutions can be deployed primarily through two methods: cloud-based/hosted services or on local machines.
Cloud-based AI services, while convenient and scalable, expose sensitive user data to potential risks, as data processing occurs on external servers and may be accessible to third parties.
In contrast, local AI environments offer enhanced security, ensuring that user data remains isolated and inaccessible to other applications or external entities. However, local environments come with significant limitations, including the need for technical expertise that is not available to the majority of users. Moreover, these environments often face performance challenges; for instance, running large language models (LLMs) on standard consumer hardware is typically impractical due to the high computational demands.
Verida’s Confidential Storage and Compute infrastructure offers alternatives to these approaches.
Apple has recently announced Private Cloud Compute that provides a hybrid local + secure cloud approach. AI processing occurs on a local device (ie: mobile phone) by default, then when additional processing power is required, the request is offloaded to Apple’s servers that are operating within a trusted execution environment. This is an impressive offering that is focused on solving important security concerns relating to user data and AI. However, it is centralized, only available to Apple devices and puts significant trust in Apple as they control both the hardware and attestation keys.
Self-Sovereign AI Interaction Model
Let’s look at what an ideal model of confidential AI architecture looks like. This is an interaction model of how a basic “Self-Sovereign AI” chat interface, using a RAG-style approach, would operate in an end-to-end confidential manner.
The End User Application in this example will be a “Chat Prompt” application. A user enters a prompt (i.e., “Summarize the conversation I had with my mates about the upcoming golf trip”).
A Private AI API endpoint (AI Prompt) receives the chat prompt and breaks down the request. It sends a prompt to the LLM, converting the original prompt into a series of search queries. The LLM could be an open source or proprietary model. Due to the confidential nature of the secure enclave, proprietary models could be deployed without risk of IP theft by the model owner.
The search queries are sent to the User Data API which has access to data previously obtained via Verida’s Private Data Bridge. This data includes emails, chat message histories and much more.
The Private AI API collates the search query results and sends the relevant responses and original prompt to the LLM to produce a final result that is returned to the user.
Verida is currently developing a “showcase” AI agent that implements this architecture and can provide a starting point for other projects to build their own confidential private AI products.
Confidential Compute
A growing number of confidential compute offerings are being offered by the large cloud providers that provide access to Trusted Execution Environments (TEEs). These include: AWS Nitro, Google Confidential Compute and Azure Confidential Compute. Tokenized confidential compute offerings such as Marlin Oyster and Super Protocol have also emerged recently.
These compute offerings typically allow a container (such as a Docker instance) to be deployed within a secure enclave on secure TEE hardware. The enclave has a range of verification and security measures that can prove that both the code and the data running in the enclave is the code you expect and that the enclave has been deployed in a tamper-resistant manner.
There are some important limitations to these secure enclaves, namely:
There is no direct access available to the enclave from the infrastructure operator. Communication occurs via a dedicated virtual socket between the secure enclave and the host machine (*).
There is no disk storage available, everything must be stored in RAM.
Direct GPU access is typically not available within the secure enclave (necessary for high performance LLM training and inference), however this capability is expected to be available in early 2025.
(*) In some instances the infrastructure operator controls both the hardware attestation key and the cloud infrastructure which introduces security risks that need to be carefully worked through, but is outside the scope of this document.
The Verida network is effectively a database offering high performance data synchronization and decryption. While secure enclaves do not have local disk access (by design), it is possible to give a secure enclave a private key, enabling the enclave to quickly download user data, load it into memory and perform operations.
While enclaves do not have direct access to the Internet, it is possible to facilitate secure socket connections between the host machine and enclave to “proxy” web requests to the outside world. This increases the surface area of possible attacks on the security of the enclave, but is also a necessary requirement for confidential compute that interacts with other web services.
It is critical that confidential AI inference for user prompts has a fast response time to ensure a high quality experience for end users. Direct GPU access via confidential compute is most likely necessary to meet these requirements. Access to GPUs with TEEs is currently limited, however products such as the NVIDIA H100 offer these capabilities and these capabilities will be made available for use within the Verida network in due course.
Self-Sovereign Compute
Verida offers a self-sovereign compute infrastructure stack that exists on top of confidential compute infrastructure.
The self-sovereign compute infrastructure provides the following guarantees:
User data is not accessible by infrastructure node operators.
Runtime code can be verified to ensure it is running the expected code.
Users are in complete control over their private data and can grant / revoke access to third parties at any time.
Third-party developers can build and deploy code that will operate on user data in a confidential manner.
Users are in complete control over the compute services that can operate on their data and can grant / revoke access to third parties at any time.
There are two distinct types of compute that have different infrastructure requirements; Stateless Confidential Compute and Stateful Confidential Compute.
Stateless (Generic) Confidential Compute
This type of computation is stateless, it retains no user data between API requests. However, it can request user data from other APIs and process that user data in a confidential manner.
Here are some examples of Generic Stateless Compute that would operate on the network.
Private Data Bridge facilitates users connecting to third-party platform APIs (ie: Meta, Google, Amazon, etc.). These nodes must operate in a confidential manner as they store API secrets, handle end user access / refresh tokens to the third-party platforms, pull sensitive user data from those platforms, and then use private user keys to store that data in users’ private databases on the Verida network.
LLM APIs accept user prompts that contain sensitive user data, so they must operate in a confidential compute environment.
AI APIs such as AI prompt services and AI agent services provide the “glue” to interact between user data and LLMs. An AI service can use the User Data APIs (see below) to directly access user data. This enables it to facilitate retrieval-augmented generation (RAG) via the LLM APIs, leveraging user data. These APIs may also save data back to users’ databases as a result of a request (i.e., saving data into a vector database for future RAG queries).
See “Self-Sovereign AI Interaction Model” from Part 1 for a breakdown of how these generic compute services can interact together to provide AI services on user data.
Stateful (User) Confidential Compute
This type of computation is stateful, where user data remains available (in memory) for an extended period of time. This enhances performance and, ultimately, the user experience for end users.
A User Data API will enable authorized third party applications (such as private AI agents) to easily and quickly access decrypted private user data. It is assumed there is a single User Data API, however in reality it is likely there will be multiple API services that operate on different infrastructure.
Here are some examples of the types of data that would be available for access:
Chat history across multiple platforms (Telegram, Signal, Slack, Whatsapp, etc.)
Web browser history
Corporate knowledge base (ie: Notion, Google Drive, etc)
Emails
Financial transactions
Product purchases
Health data
Each of these data types have different volumes and sizes, which will also differ between users. It’s expected the total storage required for an individual user would be somewhere between 100MB and 2GB, whereas enterprise knowledge bases will be much larger.
In the first phase, the focus will be on structured data, not images or videos. This aligns with Verida’s existing storage node infrastructure that provides and aids the development of a first iteration of data schemas for AI data interoperability.
The User Data API exposes endpoints to support the following data services:
Authentication for decentralized identities to connect their account to a User Data API Node
Authentication to obtain access and refresh tokens for third-party applications
Database queries that execute over a user’s data
Keyword (Lucene) style search over a user’s data
Vector database search over a user’s data
Connecting Stateful Compute to Decentralized Identities
Third party applications obtain an access token that allows scoped access to user data, based on the consent granted by the user.
A decentralized identity on the Verida network can authorize three or more self-sovereign compute nodes on the network, to manage access to their data for third-party applications. This is via the serviceEndpoint capability on the identity’s DID Document. This operates in the same way that the current Verida database storage network allocates storage nodes to be responsible for user data.
Secure enclaves have no disk access, however user data is available (encrypted) on the Verida network and can be synchronized on demand given the appropriate user private key. It’s necessary for user data to be “hot loaded” when required which involves synchronizing the encrypted user data from the Verida network, decrypting it, storing it in memory and then adding other metadata (i.e., search indexes). This occurs when an initial API request is made, ensuring user data is ready for fast access for third-party applications.
After a set period of time of inactivity (i.e., 1 hour) the user data will be unloaded from memory to save resources on the underlying compute node. In this way, a single User Data API node can service requests for multiple decentralized identities at once.
It will be necessary to ensure “hot loading” is fast enough to minimize the first interaction time for end users. It’s also essential these compute nodes have sufficient memory to load data for multiple users at once. Verida has developed an internal proof-of-concept to verify the “hot loading” concept with user data will be a viable solution.
For enhanced privacy and security, the data and execution for each decentralized identity will operate in an isolated VM within the secure enclave of the confidential compute node.
Confidential Compute Nodes
Confidential Compute Nodes running on the Verida Self-Sovereign Compute Network operate a web server within a secure enclave environment to handle compute requests and responses.
There will be different types of nodes (i.e., LLM, User API) that will have different code running on them depending on the service(s) they are providing.
For maximum flexibility, advanced users and developers will be able to run compute nodes locally, on any type of hardware.
Nodes have key requirements they must adhere to:
GPU access is required for some compute nodes (i.e., LLM nodes), but not others. As such, the hardware requirements for each node will depend on the type of compute services running on the node.
Code Verifiability is critical to ensure trust in the compute and security of user data. Nodes must be able to attest the code they are running has not been tampered with.
Upgradability is essential to keep nodes current with the latest software versions, security fixes and other patches. Coordination is required to ensure applications can ensure their code is running on the latest node versions.
API endpoints are the entry point for communicating with nodes. It’s essential a web server host operates within the secure enclave to communicate with the outside world.
SSL termination must occur within the secure enclave to ensure the host machine can’t access API requests and responses.
Resource restraints will exist on each node (i.e., CPU, memory) that will limit the number of active requests they can handle. The network and nodes will need to coordinate this to ensure nodes are selected that have sufficient resources available to meet any given request.
Interoperability and Extensibility
In order to create an efficient and highly interoperable ecosystem of self-sovereign API’s, it’s necessary to have a set of common data standards. Verida’s self-sovereign database storage network provides this necessary infrastructure via guaranteed data schemas within encrypted datasets, providing a solid foundation for data interoperability.
Developers can build new self-sovereign compute services that can be deployed on the network and then used by other services. This provides an extensible ecosystem of API’s that can all communicate with each other to deliver highly complex solutions for end users.
Over time, we expect a marketplace of private AI products, services and APIs to evolve.
Service Discovery
Verida’s self-sovereign compute network will enable infrastructure operators to deploy and register a node of a particular service type. When an API needs to send a request to one of those service types, it can perform a “service lookup” on the Verida network to identify a suitable trusted, verifiable node it can use to send requests of the required service type.
User Data Security Guarantees
It is essential to protect user privacy within the ecosystem and prevent user data leaking to non-confidential compute services outside the network. Each service deployed to the network will be running verifiable code, running on verifiable confidential compute infrastructure.
In addition, each service will only communicate with other self-sovereign compute services. Each API request to another self-sovereign compute service will be signed and verified to have been transmitted by another node within the self-sovereign network.
Tokenized Payment
The VDA token will be used for payment to access self-sovereign compute services. A more detailed economic model will be provided, however the following key principles are expected to apply.
End users will pay on a “per-request” basis to send confidential queries to compute nodes and the services they operate. The cost per request will be calculated in a standardized fashion that balances the computation power of a node, memory usage and request time. Applications can sponsor the request fees on behalf of the user and then charge a subscription fee to cover the cost, plus profit, much like a traditional SaaS model.
Node operators will be compensated for providing the confidential compute infrastructure to Verida’s Self-Sovereign Compute Network.
Builders of services (i.e., AI Prompts and Agents) will be able to set an additional fee for using their compute services, above and beyond the underlying “per-request” compute cost. This open marketplace for AI Agents and other tools drives innovation and provides a seamless way for developers to generate revenue from the use of their intellectual property.
Verida Network will charge a small protocol fee (similar to a blockchain gas fee) on compute fees.
Other Use Cases
Data Training Marketplaces
Verida’s Private Data Bridge allows users to reclaim their private data from platforms such as Meta, Google, X, email, LinkedIn, Strava, and much more.
Users on the Verida network could push their personal data into a confidential compute service that anonymizes their data (or generates synthetic data) which is made available to various AI data marketplaces. This provides an option for users to monetize their data, without risk of data leakage, while unlocking highly valuable and unique datasets such as private messages, financial records, emails, healthcare data for training purposes.
Managed Crypto Wallets
There is a vast array of managed wallet services available today that offer different trade-offs between user experience and security.
Having an always available cloud service that can protect user’s private keys, but still provide multiple authorization methods for a user is extremely useful to onboard new users and provide additional backup protection measures for existing users.
Such a managed wallet service becomes rather trivial to build and deploy on the Verida self-sovereign compute network.
Verifiable Credentials
Verida has extensive experience working with decentralized identity and verifiable credential technology, in combination with many ecosystem partners.
There is a significant pain point in the industry, whereby developers within credential ecosystems are required to integrate many disparate developer SDK’s to offer an end-to-end solution. This is due to the self-sovereign nature of credentials and identity solutions where a private key must be retained on end user devices to facilitate end-to-end security.
Verida’s self-sovereign compute network can provide a viable alternative, whereby application developers can replace complex SDK integrations with simple self-sovereign APIs. This makes integration into mobile applications (such as identity wallets) and traditional web applications much easier, simpler and viable.
This could be used to provide simple API integrations to enable:
Identity wallets to obtain access to a user’s verifiable credentials
End users to pre-commit selective disclosure rules for third party applications or identity wallets, without disclosing their actual credentials
Provide trusted, verifiable universal resolvers
Trust registry APIs
Any complex SDK that requires a user’s private key to operate, could be deployed as a micro service on Verida’s self-sovereign compute network to provide a simpler integration and better user experience.
Conclusion
Verida’s mission to empower individuals with control over their data continues to drive our innovations as we advance our infrastructure. This Litepaper outlines how the Verida Network is evolving from decentralized, privacy-preserving databases to include decentralized, privacy-preserving compute capabilities, addressing critical issues in AI data management and introducing valuable new use cases for user-controlled data.
As AI faces mounting challenges with data quality, privacy, and transparency, Verida is at the forefront of addressing these issues. By expanding our network to support privacy-preserving compute, we enable the more effective safeguarding of private data while allowing it to be securely shared with with leading AI models. This approach ensures end-to-end privacy and opens the door to hyper-personalized and secure AI experiences.
Our solution addresses three fundamental problems: enabling user access to their private data, providing secure storage and sharing, and ensuring confidential computation. Verida’s “Private Data Bridge” allows users to securely reclaim and manage their data from various platforms and facilite its use in personalized AI applications without compromising privacy.
While we are not focusing on decentralized AI model training or distributed inference, Verida is committed to offering high-performance, secure, and trusted infrastructure for managing private data. We are collaborating with partners developing private AI agents, AI data marketplaces, and other privacy-centric AI solutions, paving the way for a more secure and private future in AI. This empowers users to be confident about the ways their data is used, and receive compensation when they do choose to share elements of their personal data.
As we continue to build on these advancements, Verida remains dedicated to transforming how private data is utilized and protected in the evolving landscape of AI.